-
[삼성 SDS Brightics] ANOVA 분산분석삼성 Brightics 서포터즈 2022. 7. 12. 23:37

안녕하세요 :) Brightics 서포터즈 3기 정민경입니다.
3주간 진행되었던 mini_개인분석 과제가 이번주에 마무리되는데요,
오늘은 조금 더 가벼운 주제를 들고왔어요!
1) 주제 및 데이터 선정
그간 저는 자연어처리를 배우며 텍스트 데이터를 위주로 다뤄왔어요.
그래서 '경영통계학'와 같이 숫자를 다루는 분석기법은 어떻게 적용될까? 궁금했거든요!
간단하게 그 이론을 복습하고 반복해보고 싶어
Kaggle에서 연습 data를 가져왔답니다.
ANOVA - Diet
www.kaggle.com
남/여의 다이어트 방법에 따른 체중 변화 기록이에요.
각 다이어트 방법(A,B,C)이 구체적으로 어떻게 다른지 설명이 없어
해석까지 나아가지 못한다는 아쉬움이 있지만,
그렇게 이번주는 Brightics와 함께
명목변수(그룹별) 간 차이를 살펴보는 'ANOVA 분산분석'을 다뤄봐요!
***
아래는 본격적으로 시작하기 전, 분석 과정의 전체 Logic 입니다.
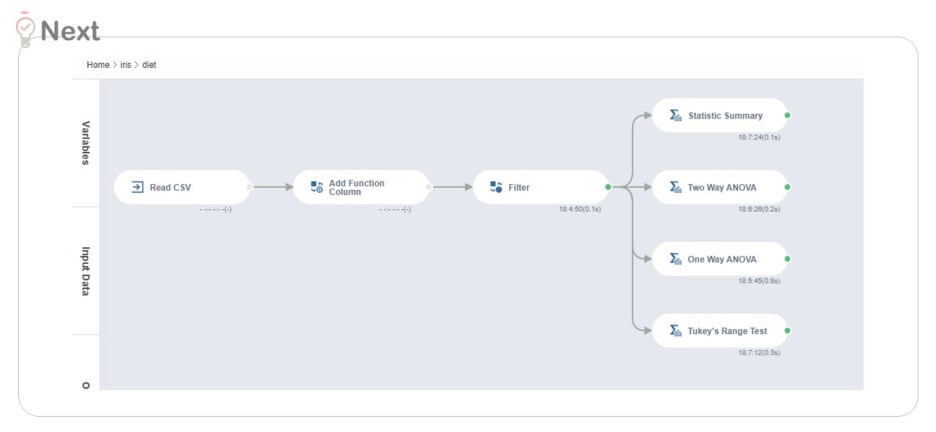
1) Data Load
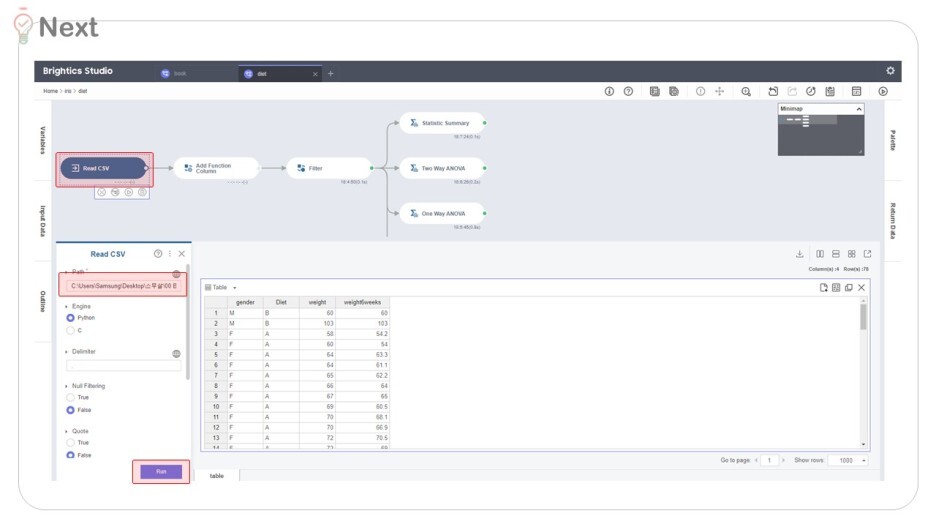
'Read CSV'로 위의 데이터를 Brightics로 가져와주세요.
weight : 다이어트 이전 몸무게
weight6weeks : 다이어트 이후 몸무게
※ 이전 포스팅과 내용이 겹쳐 요약하여 방법을 소개합니다
더 자세한 방법이 궁금하다면 이전 포스팅을 함꼐 봐주세요 ※
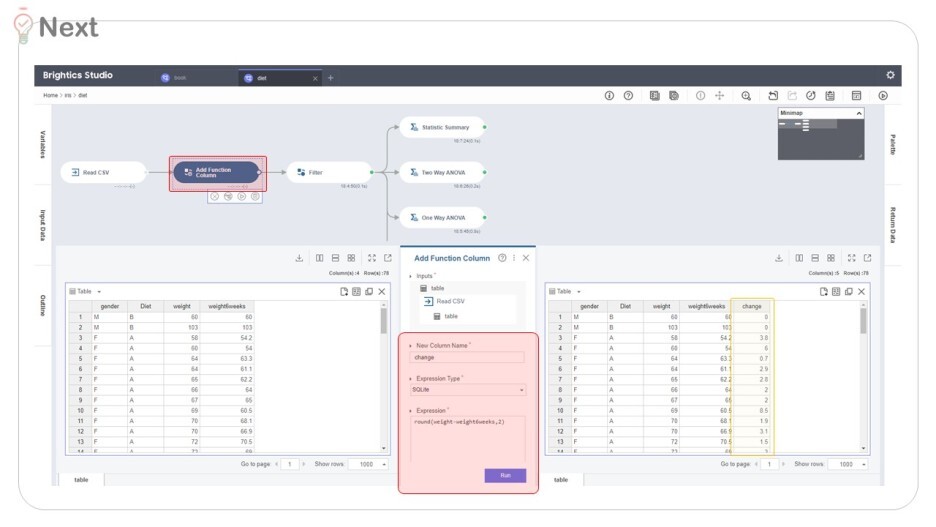
그 후, 'Add columns'로
원본데이터에 없지만 필요한 값을 추가했어요.
change : 다이어트 전후 몸무게의 변화량
식 → round (weight-weight6weeks, 3)
** round (값 , 자릿수) = 반올림 함수 **
2) Filter (데이터 전처리)
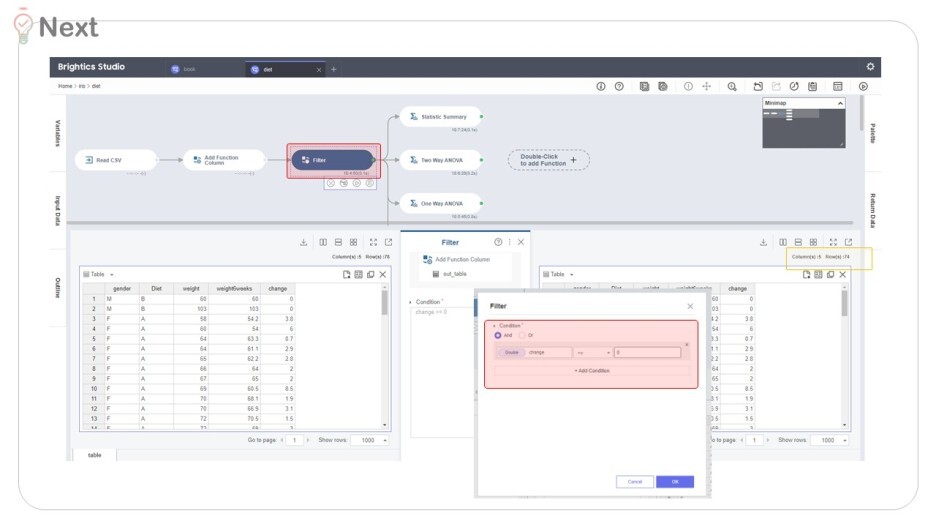
추가한 change 값을 살펴보니 음수가 있었어요.
다이어트 중 오히려 몸무게가 증가했다는 뜻인데,
이는 다른 변인이 작용했다 볼 수 있어 해당 관측치를 제거했답니다.
'Filter' 함수로 change >=0
위와 같은 조건을 줘
78개의 data가 74개로 줄어든 것을 볼 수 있어요.
3) Statistic Summary ( 데이터 EDA)
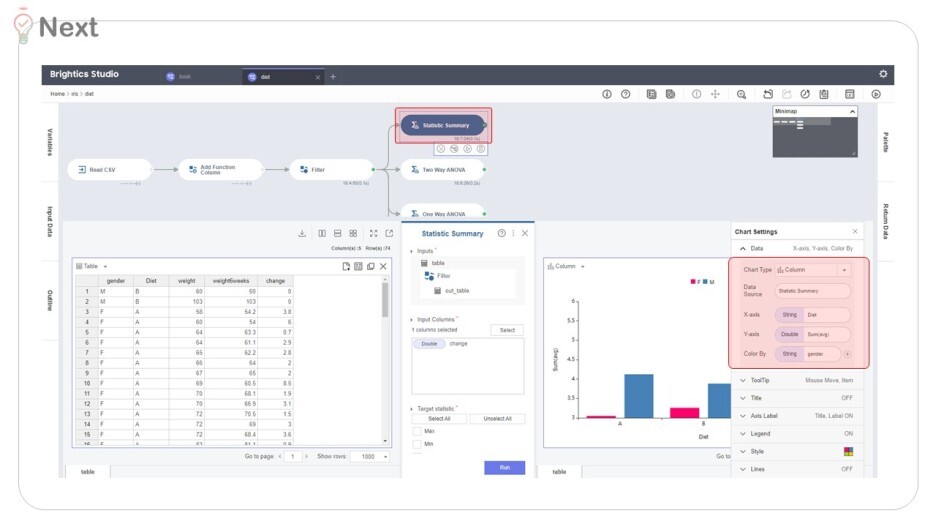
먼저, 'Statistic Summary'로
각 그룹별로 몸무게 변화량 차이를 살펴봤어요.
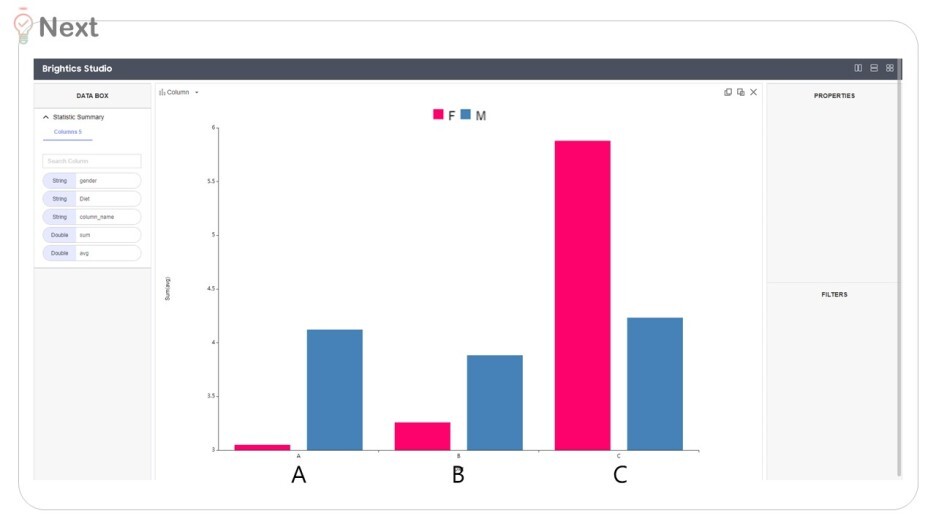
성별(남, 여) / 다이어트법 ( A, B, C)
총 6가지 그룹의
몸무게 변화량(평균)을 그래프로 나타내면 위와 같답니다.
그리고 차이가 존재하지만 - 그 차이가 유의미할까?
이를 통계적으로 검증하는 과정이 분산분석이에요!
@-@
차이가 아무리 크거나 작아도 그 값은 상대적이잖아요.
이를 더 정교하게 분석하기 위해 아래의 제곱합을 살펴봐요.
그룹간차이 (SSB) = 그룹평균 - 총평균
→ 독립변수를 요인으로 생겨난 차이
그룹내차이 (SST) = 개별값 - 그룹평균
→ 오차이자 우연으로 생겨난 차이
즉, 그룹간차이(SSB)가 그룹내차이(SST)보다 크다면
해당 독립변수가 우연이 아닌 유의미한 차이를 만들어내고 있다 볼 수 있겠죠?
여기에 '자유도'를 고려한 평균값(MSB, MSE)을 구해
F 분포에서 F값(MSB / MSE)의 p-value 를 유의수준과 비교할 거에요.
@-@
간단하게 원리를 요약해보았는데,
처음 접하는 개념이면 통계는 언제나 어렵더라고요!
◆ 원리이자 수식을 다 자세하게 정리한 ◆
분산분석 포스팅을 아래에 첨부합니다 :)
= 분산분석 Basic =
( 예전에 강의를 수강하며 정리한 내용이에요 )
경영통계학_분산분석
* 자료에 오류가 있다면 댓글 또는 메일 부탁드려요. - 2020_6학기. 경영통계학 '분산분석' 내용...
blog.naver.com
4) ANOVA (분산분석)
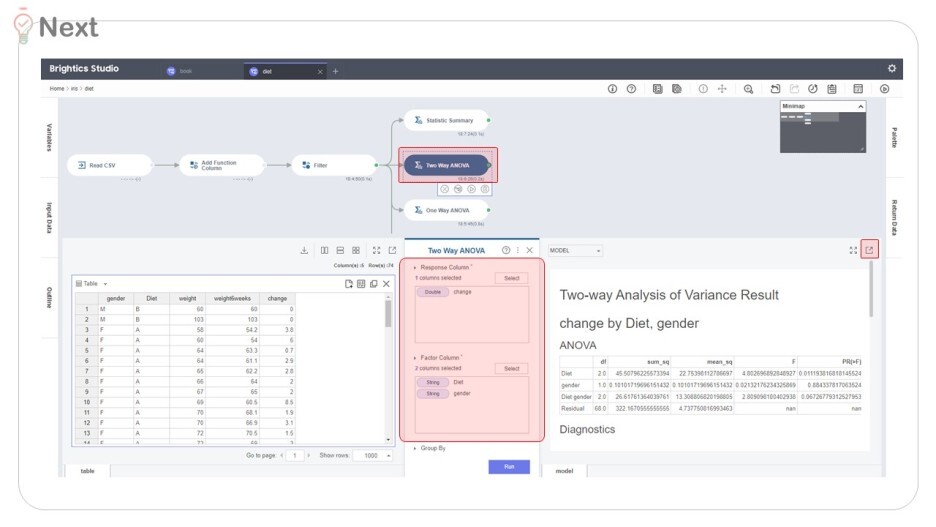
Brightics 에는 ANOVA가 두 종류 존재해요.
◆ One way ANOVA (일원분산분석) 1개의 독립변수 고려해 영향 조사
◆ Two way ANOVA (이원분산분석) 2개의 다른 독립변수의 영향 조사
그 중, '성별' & '다이어트 방법'
위 두 변수를 모두 살펴보기 위해 Two way ANOVA 를 적용했어요.
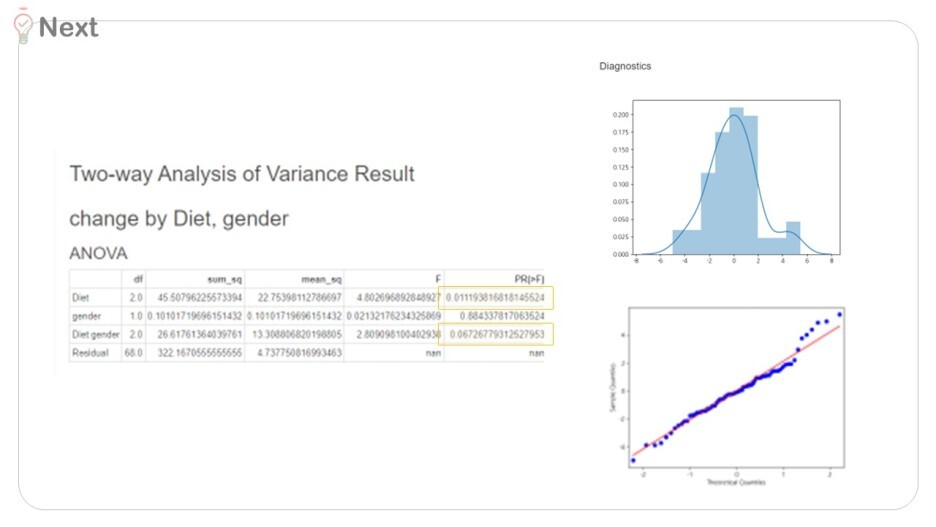
그러면 ANOVA에 필요한 가정 검증(독립성 / 정규성/ 등분산성) 및 분석 결과값이 나와요.
① 독립성 : 관측치 별 관계가 없는가 ex) 한 사람이 다이어트 A, B, C를 모두 경험한다면 연관성 지님
② 정규성 : 정규분포를 따르는가 // 심하지 않다면 중요치 않다.
③ 등분산성 : 분산이 관측값에 대해 일정 // log와 같이 변수 변환으로 해결 가능
위의 기본 가정 검증을 검토한 후
각 변수가 유의미한지 p-value 값을 살펴보자
성별 : 0.88
다이어트법 : 0.01
성별 * 다이어트법 : 0.06
( 기호 '*' 상호작용을 뜻합니다)
유의수준을 5%로 두면, '다이어트법'만이 유의미한 변수라 볼 수 있어요.
하지만 유의수준은 분석마다 기준이 다르게 적용되어 10%로 결정되기도 하는데요,
아주 미세한 차이로 6%를 지닌 '성별 * 다이어트법'을 보류하며 넘어갔습니다.
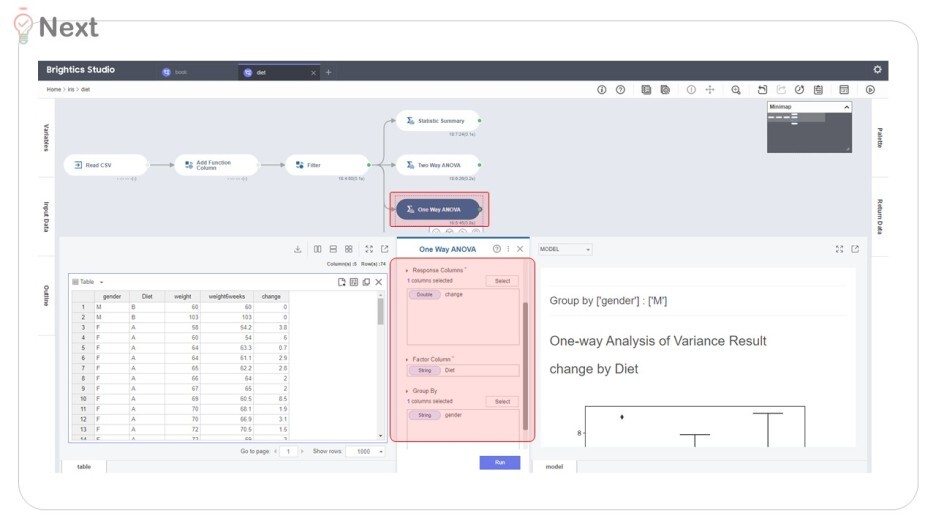
왜냐, One way ANOVA 에서
Response col (Y 변수) : 몸부게 변화량 change
Factor col (X 변수) : 다이어트법 Diet
Group by (그룹) : 성별 gender
유의미한 '다이어트법'을 독립변수로
각각의 '성별'을 나누어 살펴보자
두 그룹사이에 차이가 있었기 때문이에요.
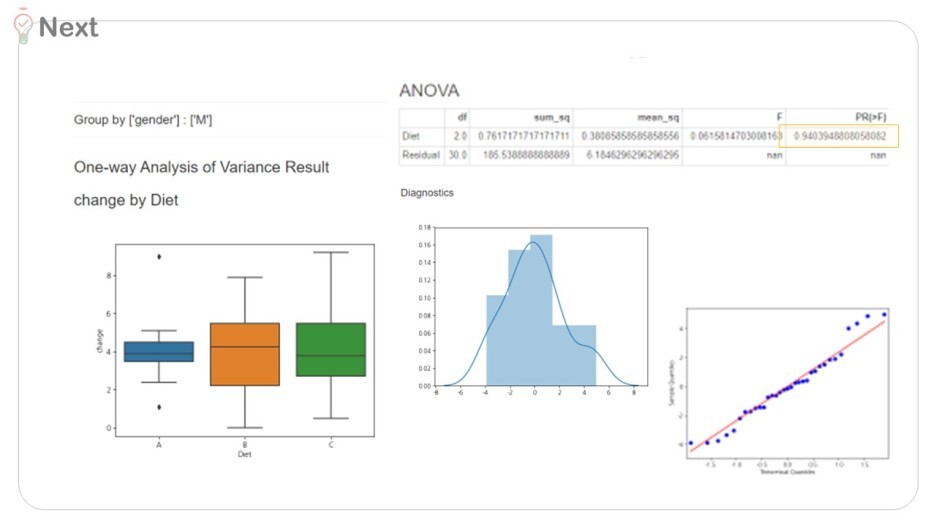
남성(M)의 경우 'Diet'의 p-value 값은 0.94로
유의미하다 볼 수 없지만
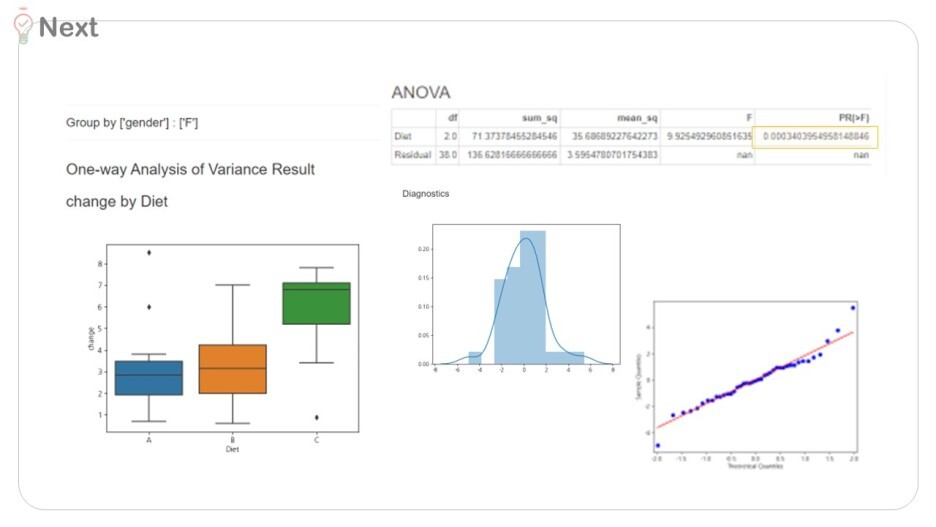
여성(W)의 경우 'Diet'의 p-value값은 0.0003
즉, 유의미한 차이를 만들어내고 있었답니다.
5) Tukey Range Test (사후검정)
이어서
그렇다면, 구체적으로 각 그룹이 어떻게 다른데?
질문하는 과정이 사후검정이에요!
'다이어트법'이 몸무게 변화에 유의미한 영향을 주는데,
그 방법에는 A,B,C 총 3가지의 방법이 있어서
각 방법을 두가지씩 짝지어 비교해요.
LSD 등 여러 방법이 존재하는데
Brightics 에는 Tukey 검정이 있답니다.
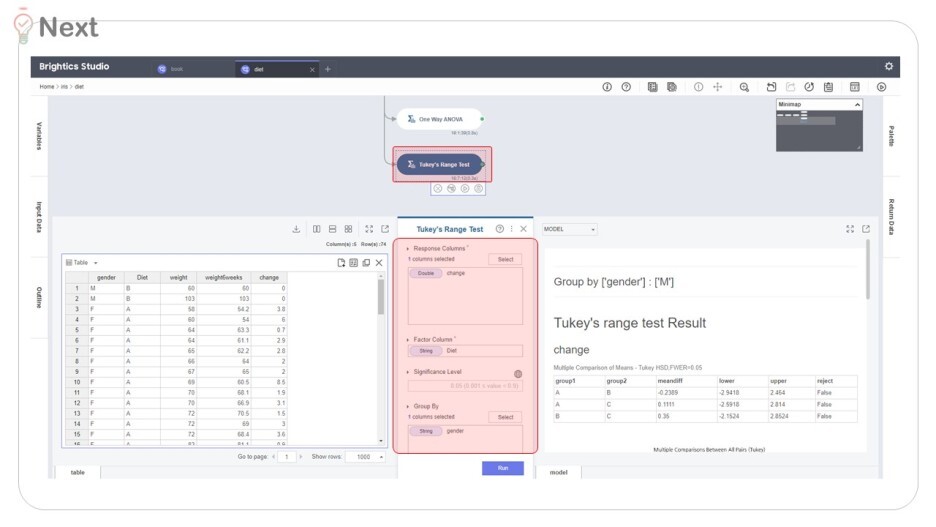
One way ANOVA 와 동일하게 변수를 주면
Response col (Y 변수) : 몸부게 변화량 change
Factor col (X 변수) : 다이어트법 Diet
Group by (그룹) : 성별 gender
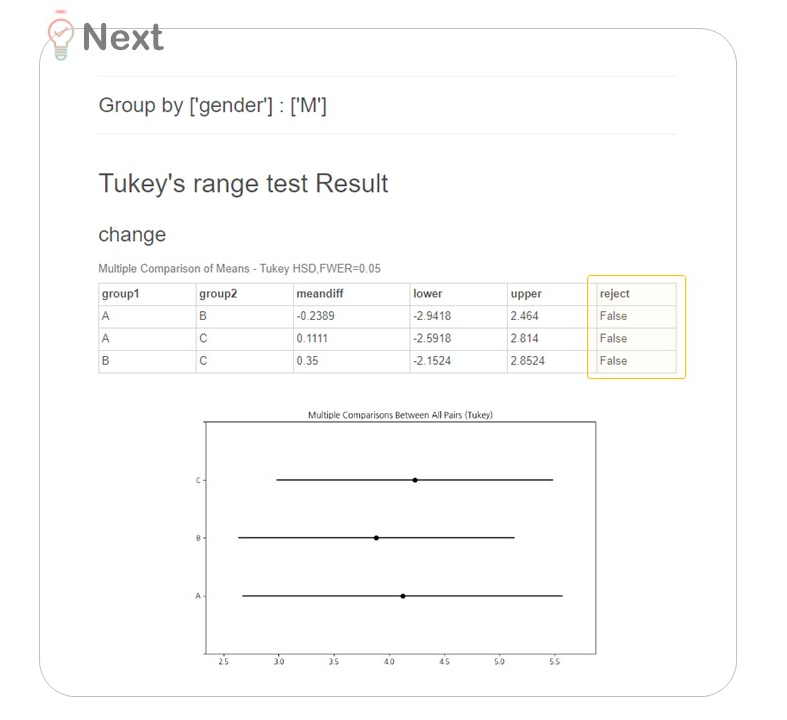
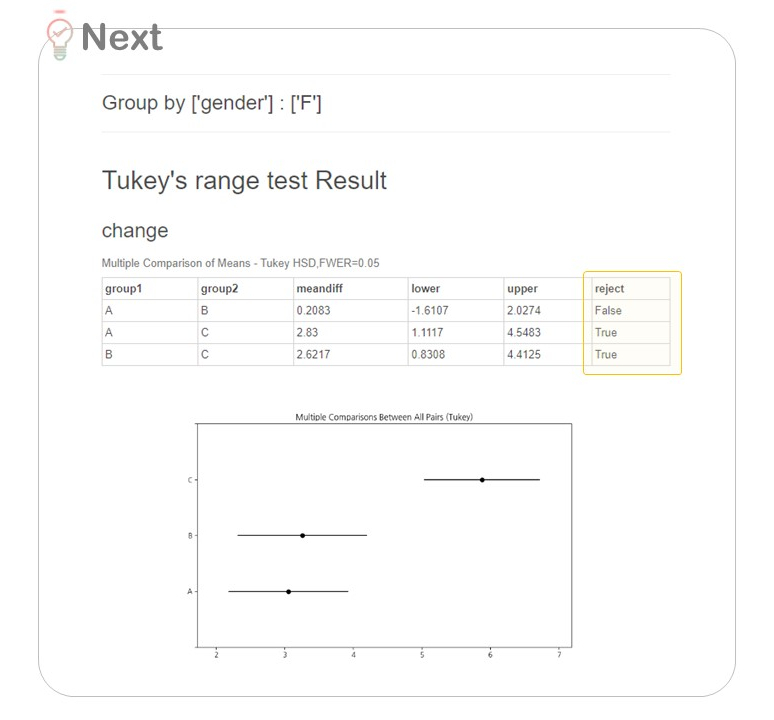
각 A, B, C 그룹을 짝지어서 비교하고 있죠!
여기서 'reject'란,
귀무가설을 기각하고 대립가설을 채택함의 의미해요.
귀무가설 H0 - 두 그룹 간에는 차이가 없다
대립가설 H1 - 두 그룹 간에는 차이가 있다
True 이면, 두 그룹 간의 차이가 있다 (H1)
False 이면, 두 그룹 간의 차이가 없다 (H0)
위에서 보았듯, 남성에게 다이어트법은 유의미한 변수로 작용하지 않지만
여성에게는 A-B 를 제외한 C-A / C-B 그룹 간에 유의미한 차이를 볼 수 있었어요.
'C' 다이어트법이 구체적으로 무엇인지 파악한다면
여성에게 유의미한 다이어트 방법 특징을 분석할 수 있겠죠?
그에 대한 설명이 없어 여기서 마치지만, 궁금하네요!!ㅠㅠ
Review
ANOVA 분산분석을 위에서 다뤄보고
저번주에 본 인기대출도서가
'장르' 기준으로 대출건수에 차이가 있을까?
궁금해져 추가로 더 분석을 진행했어요.
한 포스팅에 두 가지 내용을 담으면 복잡할 거 같아
추후에 천천히 정리해보려합니다 :)
이상으로 이번주 포스팅을 마칩니다!
※본 포스팅은 삼성SDS Brightics 서포터즈 3기 활동의 일환으로 작성하였습니다
'삼성 Brightics 서포터즈' 카테고리의 다른 글
[삼성 SDS Brightics] 개인 의료비 예측(2) (0) 2022.08.23 [삼성 SDS Brightics] 개인 의료비 예측(1) (0) 2022.08.16 [삼성 SDS Brightics] 지역별 산업재해 현황 분석 (0) 2022.06.28 [삼성 SDS Brightics] 서포터즈 발대식 후기 ♥ (0) 2022.06.28 [삼성 SDS Brightics] Brightics Studio 다운로드부터 실행까지! (0) 2022.06.20