-
[삼성 SDS Brightics] 개인 의료비 예측(1)삼성 Brightics 서포터즈 2022. 8. 16. 23:20

안녕하세요ㅎㅎ 저번 한달간 KETI 경진대회를 준비하고
다시 Brtightics 포스팅으로 돌아왔습니다!
이번에는 팀-분석 프로젝트인데요,
제가 만난 조원들이 너무 재밌고 좋아서 즐겁게 진행하고 있어요!ㅎㅎ
대외활동 여러개 해봤지만.. 회의할 때마다 계속 웃으면서 끝나는거 같아요.
그래서 저번주에는 다같이 만남 겸 맛집탐방을 하고왔는데
편하고 어색하지 않고 이것저것 장난 치느라 스트레스가 해소 되었답니다ㅋㅋ
너무 고마웠어요 :)
그럼 이번주는 간단하게 팀분석
주제부터 기획, EDA를 포스팅해보려고 해요!
1) 주제선정
저희는 분석주제와 그에 맞는 데이터셋을 각각 2개씩 찾아
투표로 그 중 하나를 골랐어요.
Medical Cost Personal Datasets
Insurance Forecast by using Linear Regression
www.kaggle.com
바로 Kaggle의 '개인 의료비 예측'입니다!
아쉽게 미국 data라서
이를 더 확장시켜 한국의 의료비를 살필 수 있을지도 알아보고 있는데요,
주제가 사소해보여도 자세히 파악하다보면 의미가 발견되고
나중에 또다른 재밌는 분석으로 연결되는거 같아요.
그러한 관점에서 인사이트를 발견하러! 탐색해 볼 예정입니다.
2) Data-set 확인
간단히 변수를 보면, 아래와 같이
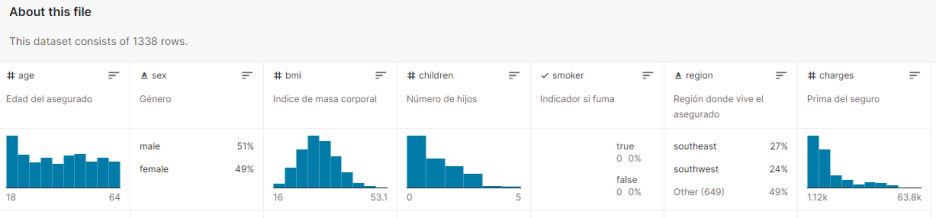
age(나이)- sex(성별)- bmi(비만지수)- 자녀수(children)- 흡연여부(smoker)- 지역(region)
의료비(charges)를 확인할 수 있어요.
즉, 6가지의 설명변수를 통해 '의료비'라는 종속변수를 예측해 볼 거에요.
3) EDA
이를 위해 이어서 진행한 Brightics를 통한 EDA 입니다!
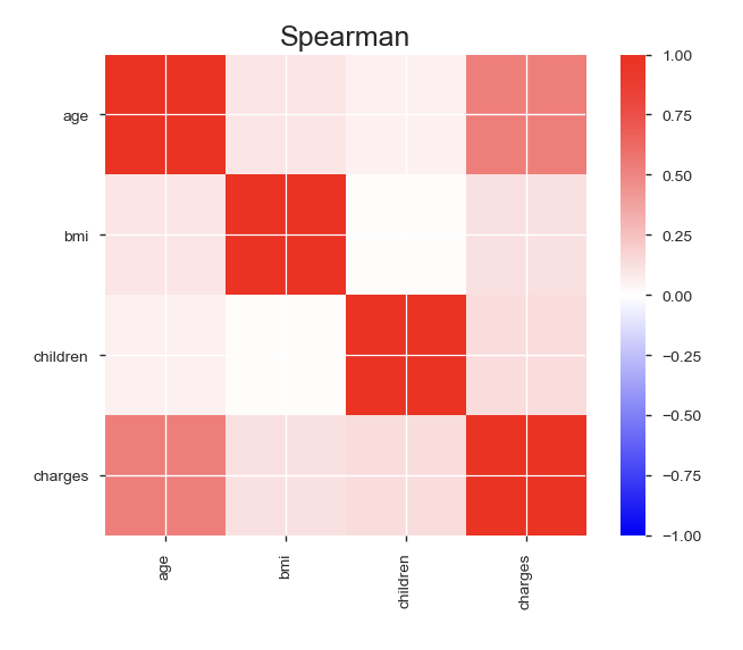
가장 먼저, 종속변수인 charge(의료비)와 관련해
age(나이)와의 상관관계가 눈에 띄고
설명변수끼리 비교했을 때
children(자녀수)와 bmi(비만지수) 간의 상관관계가 낮아
두 변수가 서로에게 영향주지 않는 독립성을 확인할 수 있어요.
(다중 변수를 살필 때는 설명변수가 서로 독립성을 지녀야 하거든요!
설명변수 x1이 이미 다른 x2를 설명할 수 있다면
x1, x2가 y에 주는 영향을 정확하게 평가할 수 없기 떄문이에요)
① age(나이) -> charge(의료비)
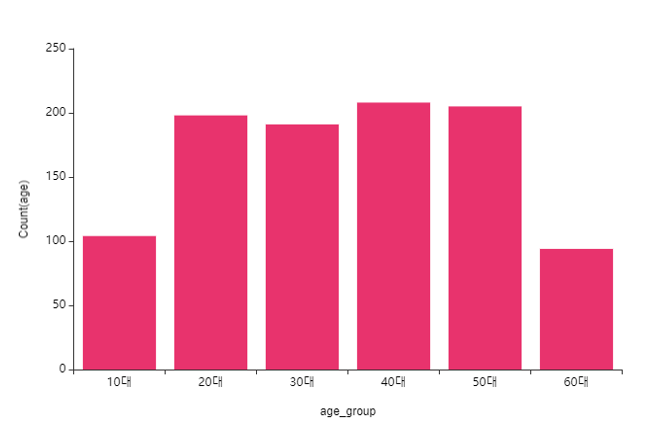
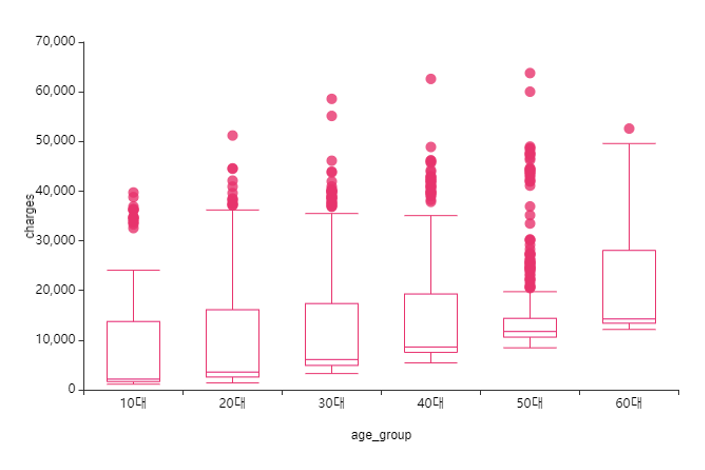
왼쪽은 나이대별 표본수
오른쪽은 나이대별 의료비 분포 양상이에요.
'표본이 적은 10대와 60대에는 병원에 적게 오는 것일까?'라는 의문과 같이
나이가 증가할 수록 의료비가 높아지는 양상이 보여요.
특히, 50대에 의료비 분포가 특이한 것이
관련한 다른 이유가 있나? 궁금해지네요!
② sex(성별) -> charge(의료비)
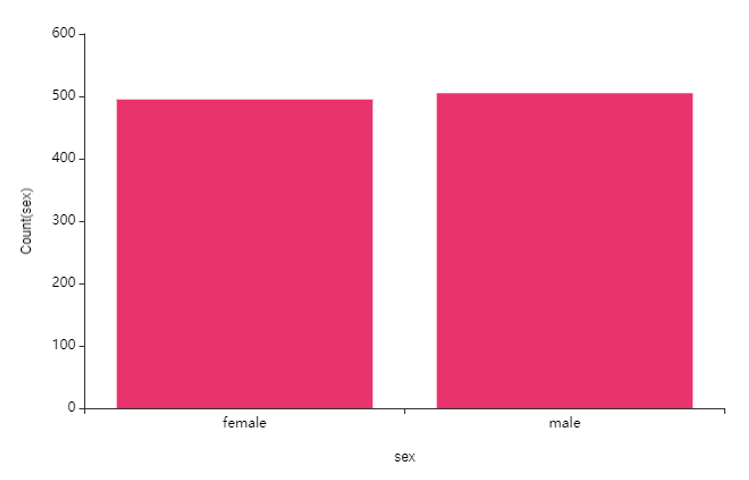
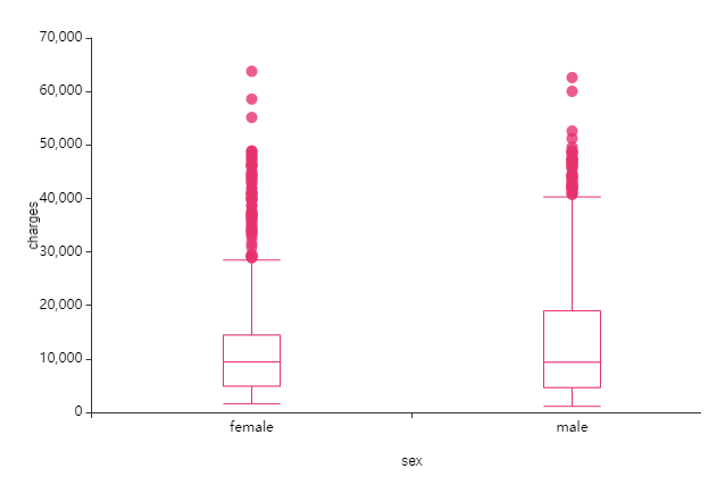
남/여의 표본수 차이는 커보이지 않고요,
그렇지만 남성에 비해 여성에게 이상치 값이 더 많이 존재해서
sex(성별)에 따라 특이질환의 유무가 다른걸까? 질문이 들었어요.
③ region(지역) -> charge(의료비)
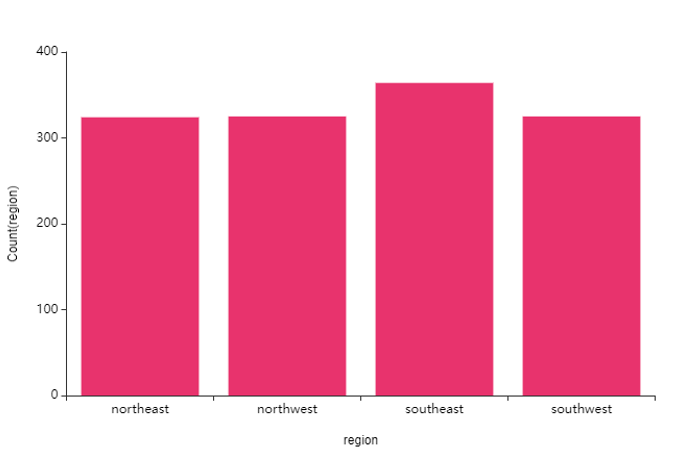
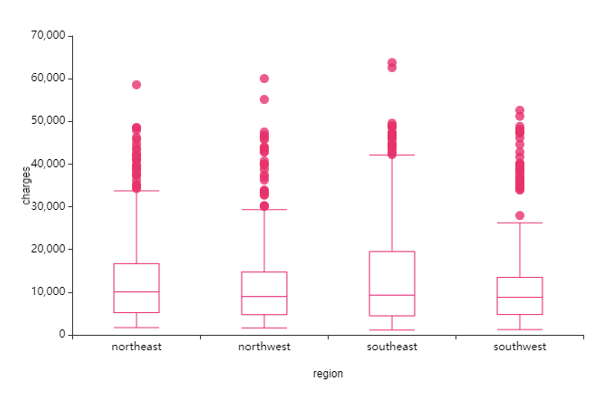
지역의 표본수 차이도 커보이지 않아요,
지역에 따른 의료비 차이도 커보이지 않은데
분포 그 자체로 보면
northwest, southwest / northeast, southeast
두 그룹으로 나뉘어요.
아무래도 west - east 간에 차이가 있어 보이네요!
④ smoke(흡연여부) -> charge(의료비)
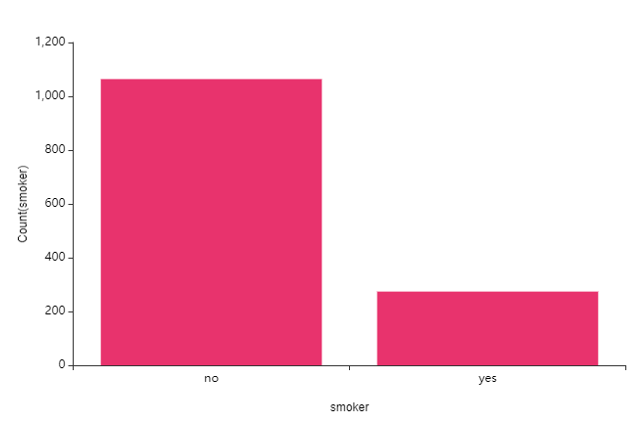
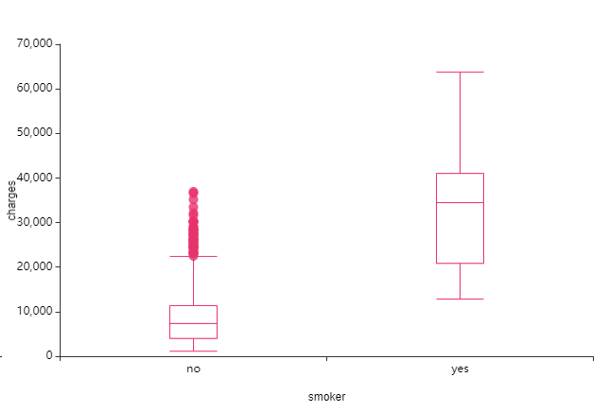
흡연여부는 표본수의 차이가 있어 보여요.
이로 인한 한계가 있는지 살펴봐야 겠지만,
동시에 쉽게 예상할 수 있듯, 흡연자의 의료비가 더 높답니다.
이상치도 없이 흡연하는 사람의 높은 의료비가 분포하는 것을 보면
smoke(흡연여부)가 의료비에 중요한 영향을 주고 있다 추론되어요.
⑤ children(자녀수) -> charge(의료비)
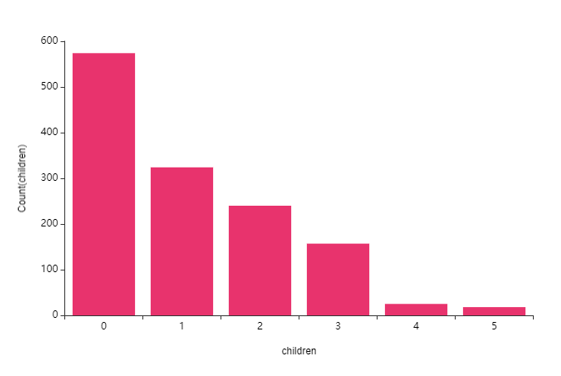
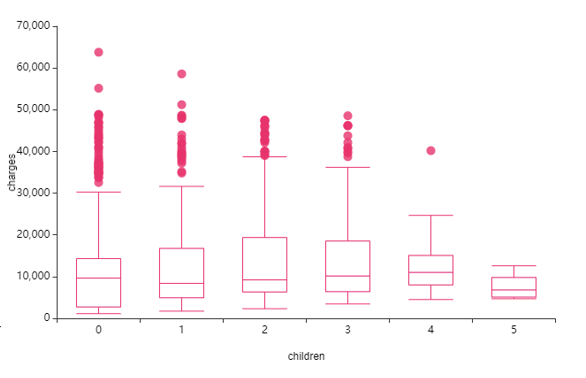
아이를 1-2명만 선호하는 변화와 같이
자녀수가 많을 수록 표본수가 적어지는 양상을 보이네요!
그리고 자녀 0명과 1-2명을 비교해보면
자녀수가 많을 수록 의료비가 높아질 거라는 예상을 벗어납니다.
자녀가 적어도 그 단 한 아이에게 집중하며 의료비가 가중되는 걸까요?
눈 여겨볼 지점인거 같아요!
⑥ BMI(비만지수) -> charge(의료비)
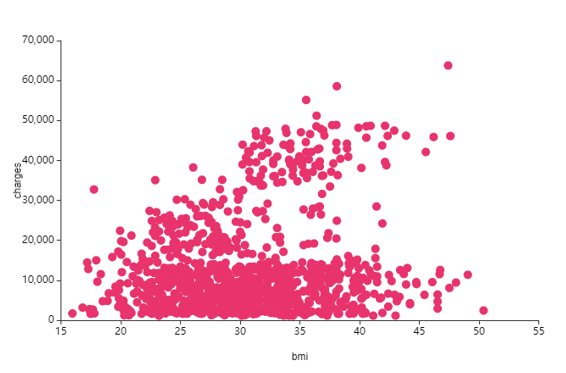
비만지수와 의료비는 모두 수치 데이터이기에 산점도를 그릴 수 있었어요.
예상과 같게 일정부분 bmi(비만지수)가 높을수록 charge(의료비)가 높아지는 관계를 가져요.
그런데 나아가 두가지 변수를 함꼐 그래프로 나타내며
세부요인을 살펴보았는데요
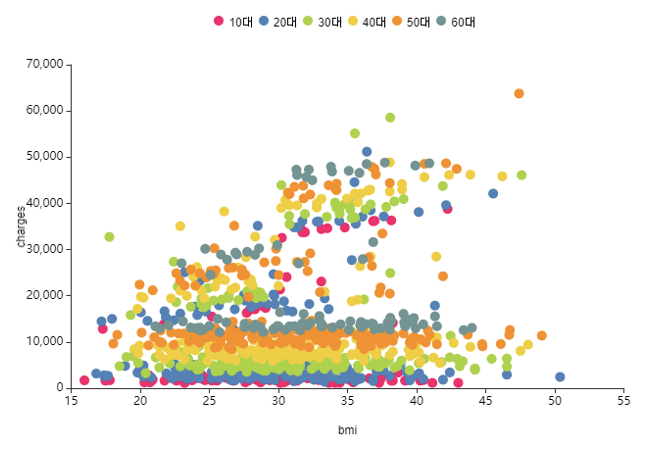
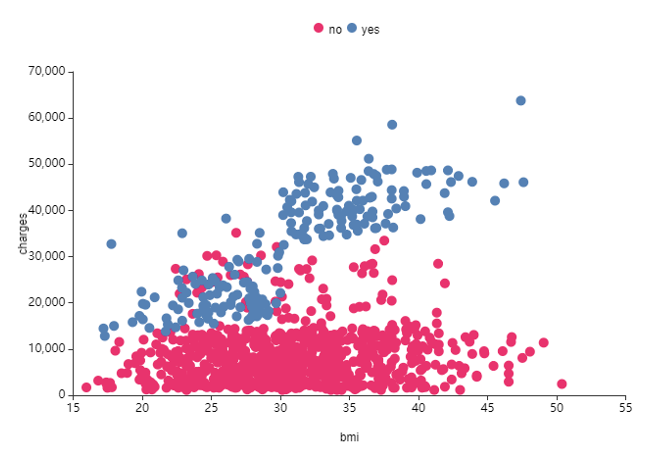
sex(성별), region(지역).. 다른 변수와 다르게
age(나이)와 smoke(흡연여부)의 경우
산점도가 그룹 지어져서 뚜렷하게 구분되는 것을 볼 수 있어요.
-같은 bmi 수치여도 나이대에 따라 의료비가 달라지며-
- 흡연자일 때 비만도와 의료비는 양의 상관관계를 가진다 -
>> 비흡연자이면 bmi가 charge(의료비)에 영향을 주지 않지만
흡연자면 bmi가 높을 수록 charge(의료비)가 높다.
☞ 비만도/나이/흡연여부를 같이 고려할 때
의료비 예측이 더 뚜렷해질 것 같다는 추측을 해봐요!
Reivew
이상, 위의 EDA를 바탕으로 한걸음 더 나아간 분석을 기약하며
이번주 팀프로젝트 포스팅을 마칩니다 :)
※본 포스팅은 삼성SDS Brightics 서포터즈 3기 활동의 일환으로 작성하였습니다
'삼성 Brightics 서포터즈' 카테고리의 다른 글
[삼성 SDS Brightics] 팀 영상 컨셉 : 유한상사 (0) 2022.09.15 [삼성 SDS Brightics] 개인 의료비 예측(2) (0) 2022.08.23 [삼성 SDS Brightics] ANOVA 분산분석 (0) 2022.07.12 [삼성 SDS Brightics] 지역별 산업재해 현황 분석 (0) 2022.06.28 [삼성 SDS Brightics] 서포터즈 발대식 후기 ♥ (0) 2022.06.28