-
[삼성 SDS Brightics] 개인 의료비 예측(2)삼성 Brightics 서포터즈 2022. 8. 23. 23:38

안녕하세요.ㅎㅎ Brightics 서포터즈 3기 정민경입니다.
저번주에 이어서 팀미션 2주차를 진행하고 있어요.
EDA를 마치고 본격적으로 의료비 예측 모델을 구현해보고 있답니다.
그 중, 저는 이후 더 진행할 Random Forest, Xgboost 등. 여러 model에 있어서
가장 기초가 될 모형으로 Linear Regression을 맡아
최종적으로 정리된 데이터로 다중회귀분석을 시도해보았어요.
팀원들의 도움을 으쌰으쌰 받으며
성공적으로 마쳤답니다. :)
- 전체 logic -

아무래도 팀 분석이라 그런지 과정이 아주 복잡하죠..ㅎㅎ
한 화면에 담가지 않을 정도로
5명 모두가 이것저것 시도하면서 분석을 확장시켰어요.
그중에서도 빨간색으로 표시된 3단계를 오늘 포스팅에서 소개하고,
그 아래에 무지 많은 또다른 함수(과정)들!!
아마 차례로 다음주에 더 진행될 예정입니다.
1) Linear Regression Train
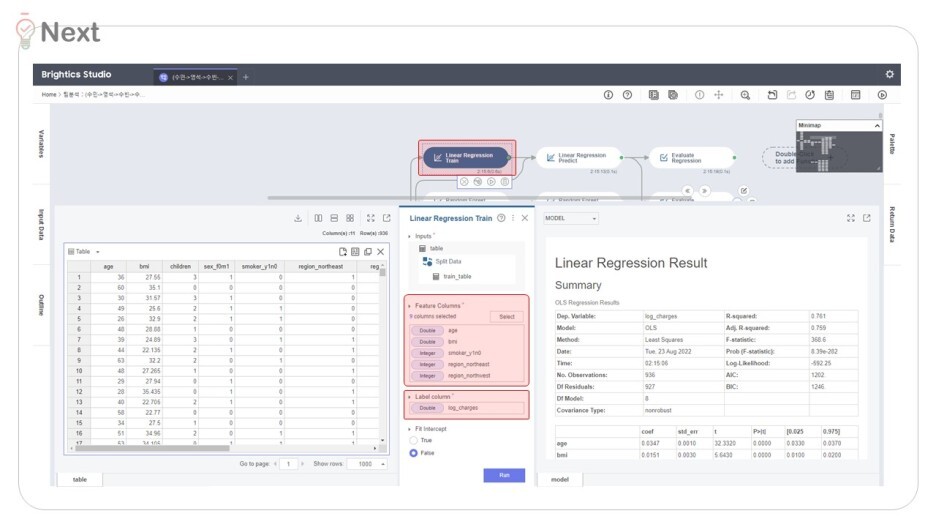
의료비 예측하는 모델을 train(훈련)하는 과정이에요.
기존의 데이터를 '학습'시킨다 표현하는데,
고려할 X변수(독립변수)와
이를 바탕으로 예측할Y변수(종속변수)를 지정해주세요.
즉, 앞서 소개한 -나이, 비만지수, 자녀수, 지역 등 - 변수로
의료비를 예상해 볼 거에요!
그 첫번째로 다중회귀분석을 시도했어요.
단순회귀분석에서 한걸음 더 나아가, 단 하나의 X변수와 Y변수가 아닌
여러개의 X변수와 Y변수의 관계를 살피는 방법이에요.
실제로 저희의 일상을 떠올려보면 오로지 하나가 원인이 되는 경우는 드물잖아요!?
여럿이 복합적으로 얽혀 영향을 주죠. 그러한 상호작용을 고려합니다.
그런데 이때, X와 Y의 관계를 선형으로 가정하여

위와 같이 식을 세워 각 회귀계수(beta)를 추정하고
정확도를 R-square, MSE, F검정의 방법으로 나타내요.
**그 자세한 원리와 의미에 대해, 다중회귀분석을 정리했던**
예전 포스팅을 아래에 첨부합니다 :)
통계자료분석_다중회귀분석
* pdf를 분할하여 올립니다. 하나는 빈 파일이지만, 같이 다운받아야 실행 가능해요. 두 파일을 함께 압축 ...
blog.naver.com


그러면 Brightics 에서 위와 같이 R-square 값부터 각 변수의 회귀계수까지,
표로 깔끔하게 정리되어 나오는 것 보이시나요?
그와 함께 predict값과 actual값을 비교한 그래프 및
다중회귀분석의 기본 가정을 검증하는 과정까지 보여줍니다.
2) Linear Regression Predict

이후 위에서 구한 다중회귀분석 식을 사용해
실제로 predict(예측) 해볼 수 있어요.
새로운 값이 들어왔을 때, 해당 x변수를 넣어 원하는 y값을 예상하는데요,
저희는 한 번 더 정확하게 모델을 Evaluate(평가)하기 위해
기존의 데이터를 predict 하는 과정을 거쳤습니다.
다시 말해, 본래의 데이터를 앞서 구한 다중회귀분석 모델에 대입해
predict-예측값을 구하고, actual-실제값과 비교해보는거죠!
3) Evaluate Regression

그렇게 'Evaluate Regression' 함수를 사용하면
모델을 더 자세한 지표로 바라볼 수 있게 도와줘요!

가장 대표적으로 나와있는 r2_score와 MSE.
r2_score가 높을수록
MSE가 낮을수록
좋은 모형임을 뜻해요!

그래서 실제로 변수를 조금 다르게 해서
위의 과정을 똑같이 실행해보았을 때 비교해보자면
('지역이 의료비에 영향이 없지 않을까?'라는 추측으로 제외해보았어요.)

predict(예측값)과 actual(실제값)의 관계가 애매해지고
무엇보다 Train에서는 더 높아보이는 R-squared 와 다르게
Evalute에서 r2_score가 음수임을 확인할 수 있어요.
이는 모델이 엉망임을...뜻한답니다..ㅎㅎ
즉, 예상과 달리 지역이 의료비 예측에 중요한 역할을 하고 있더라고요.
@@
위의 두 지표가 중요한 이유!!
다중회귀분석에서 x변수가 많을 수록 정확도가 높아질 것 같지만
x변수끼리 이미 연관성을 지녀서 영향이 과중되거나(=다중공선성)
오히려 영향없는 변수를 넣으면서 정확도가 낮아질 수 있어요.
그렇게 여러 변수의 조합을 시도해보았는데, 저희가 사용한 의료비 데이터에서는
주어진 x변수를 모두 사용할 때 가장 높은 정확도를 가지더라고요.
추후 이 점을 고려해 더 정확도가 높은 model을 찾아가야겠죠!?
Review
단순회귀도 그렇고, 다중회귀도 그렇고.
통계의 기본이 되는 내용으로
데이터를 배우면 모두가 거쳐가는 이론일거에요.
그 당시 분명 이론을 꼼꼼히 따라갔는데도 실습은 쉽지 않았던 기억이 나요.
검색으로 해결하려 하지만, 워낙 정보가 넘치다보니 무엇도 확신할 수 없어서
'이게 맞나?' 확실치 않은 부분이 생기더라고요.
그래서 숫자 data를 다루는 것에 아쉬움이자 어려움이 있었는데
이번에 팀원들에게 궁금한 것을 거리낌없이 물어보고
확신을 같이 쌓아올리며 더 단단하게 분석해볼 수 있어서 좋았어요.
log변환이 필요할지, 데이터전처리는 어느범위로 할지.
어떤 변수를 넣어야하는지. 서로 토의하면서
혼자 진행할 떄보다 더욱 균형잡힌 분석이 가능함을 몸소 실감했네요 :)
이제 담주에는 다양한 model을 접할텐데..!!
그때에도 친구들과 적극적으로 논의하며
그동안 부족했던 배움을 채워나가고 또 나누기를 바라며!ㅎㅎ
이번주 팀프로젝트 포스팅을 마칩니다 :)
※본 포스팅은 삼성SDS Brightics 서포터즈 3기 활동의 일환으로 작성하였습니다
'삼성 Brightics 서포터즈' 카테고리의 다른 글
[삼성 SDS Brightics] 팀 영상 촬영_발연기ㅎㅎㅎ (1) 2022.09.21 [삼성 SDS Brightics] 팀 영상 컨셉 : 유한상사 (0) 2022.09.15 [삼성 SDS Brightics] 개인 의료비 예측(1) (0) 2022.08.16 [삼성 SDS Brightics] ANOVA 분산분석 (0) 2022.07.12 [삼성 SDS Brightics] 지역별 산업재해 현황 분석 (0) 2022.06.28