-
[삼성 SDS Brightics] 개인 분석 프로젝트 : TF-IDF삼성 Brightics 서포터즈 2022. 10. 26. 01:25

안녕하세요.ㅎㅎ Brightics 서포터즈 3기 정민경입니다.
조금씩 활동이 막바지를 향해 달려가고 있어요.
개인분석 프로젝트도 절반 가량 지나각 즈음에,
저번주에 간략하게 포스팅했었죠!
TF-IDF와 그 결과를 이번주에 본격 분석하려해요,
"도서리뷰에는 어떤 단어가 등장할까?"
시작하며 던졌던 -가장 궁금했던- 질문을 파헤치러 GO GO!!ㅎㅎ

** 보완 1) 불용어 전처리 **
일단, 저번주에 짧게 언급했었지만
실제 결과를 살펴보면서 보완하고 싶은 점이 있었는데요,
바로 불용어 전처리!!

보시다시피 가장 위에 book, read 단어가
도서리뷰에서 많은 비중을 차지함을 볼 수 있어요.
하지만 그 두 단어가 긍정/부정의 의미를 내포하고있는가?
그렇지 않죠!
리뷰를 쓰다보면 당연히 자주 등장하는 단어이지만
뜻을 결정하는데에 역할을 하지는 않으므로
표준적인 불용어에 속하지는 않아도
현재 진행하는 분석 주제에는 불용어라 볼 수 있어요.

그래서 해당 어휘를 불용어 리스트에 추가--하면서
전체 logic을 다시 돌렸답니다.ㅎㅎ
** 보완 2) TF-IDF란? **
(Term Frequency - Inverse Document Frequency)
TF ▶ 단어의 등장 횟수
IDF ▶ DF의 역수이자 반비례 수
(DF ▷ 단어가 등장한 문서의 수)
∴ TF-IDF
= 단어의 등장 횟수 * log( 총 문서의 수 N / 단어가 등장한 문서의 수 )
※ 이때, 분모가 0이 되는 것을 방지하기 위해 +1 @ 숫자가 기하급수적으로 커지는 것을 방지하기 위해 log
단어가 자주 등장하면 그만큼 중요하겠지만,
한편 그 단어가 등장한 문서 자체가 많다면 중요도가 낮다고 볼 수 있겠죠.
대표적으로 앞서 전처리한 불용어가 있어요
수많은 문서에 등장하지만 커다란 의미는 없는!!
이를 고려하기 위해 TF(단어 등장 횟수)에
DF(단어가 등장한 문서의 수)라는 제약을 거는 거에요.

TF-IDF 를 python으로 구현하기 위의 코드를 참고해
Brightics에서는 아래와 같이 구현했답니다!

logic 
Bag of Words 의 결과 중,
document_frequency = DF = 단어가 등장하는 문서의 수
term_frequency = TF = 단어의 등장 횟수
&
총 도서리뷰의 수(11997) = N = 총 문서의 수
▶ term_frequency*log(11997/(document_frequency+1)) ◀

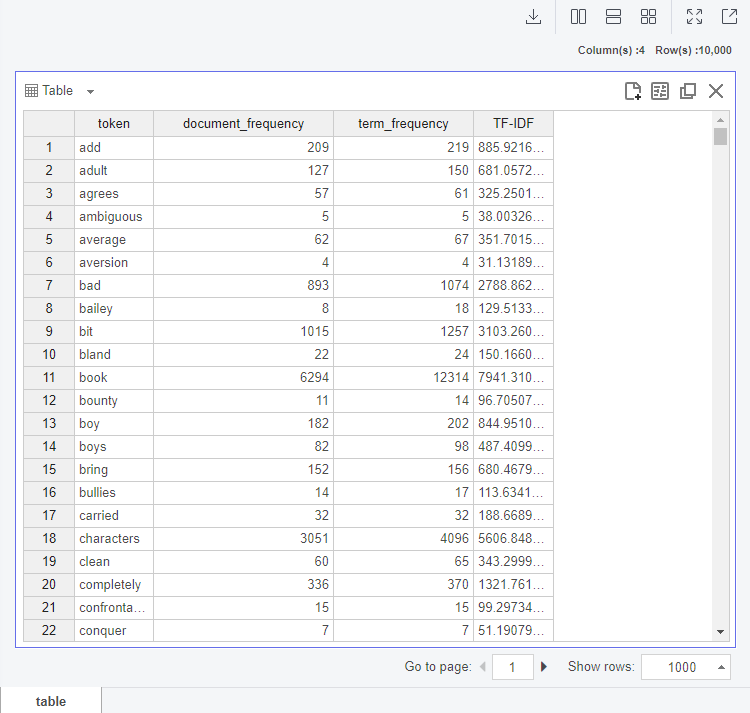
Bag of Words > Add Function Column 그런데 반전이 있었죠ㅋㅋ
바로 브라이틱스에 TF-IDF 함수가 구현되어있던 것ㅎㅎ

그리고 저번주에 멘토님의 피드백 덕분에
브라이틱스에서 제공하는 TF-IDF는
자체적인 최적화 기능이 있음을 알 수 있었어요.
가차없이 브라이틱스로 갈아탔답니다.ㅎㅎㅎ
↓↓ TF-IDF로 중요 단어를 긍정/부정 나눠서 살펴본 결과에요 ↓↓
@ 종류에 따라 분류해봤어요.

1) 먼저, 당연한 내용이지만 부정어(not)는
부정리뷰에서 더 언급이 자주 있었어요.
같이 살펴보면 good, great와 같은
좋은 뜻의 형용사가 순위권에 있음이 보이는데요,
다들 not과 함께 쓰여 부정의 의미로 쓰였을 수도 있겠다는 맥락을 추측해봐요.
그러면서 not과 함께 쓰인 단어들은
그 의미를 반대로 줘버리는 기능이 있다면 분석에 용이하겠다...!!는
생각을 했답니다.

2) 대망의 감정 형용사들.
이 유형의 단어들은 조금 아래의 순위에서 긍/부정의 차이가 도드라지더라고요.
그치만 도서리뷰에 쓰이는 단어들도 그 외 리뷰들과 비슷하다 느꼈는데요,
pos VS nag
'즐겁다' '추천한다' / '무료하다' '실망스럽다'
'진짜같다(real)' '쉽다(easy)' / '어렵다(hard)'
나도 모르게 몰입해서 어느새 시간이 후딱 지나가버린,
그럴 때 재미를 느끼는 것은 마찬가지인거 같아요.


3) 기타 책 내외부 요소, 장르와 같은 어휘도 살펴봤네요.
특히, 장르보면 romance가 긍부정 모두 Top 순위에 있어요.
그래서인지 관련 어휘가 많더라구요.

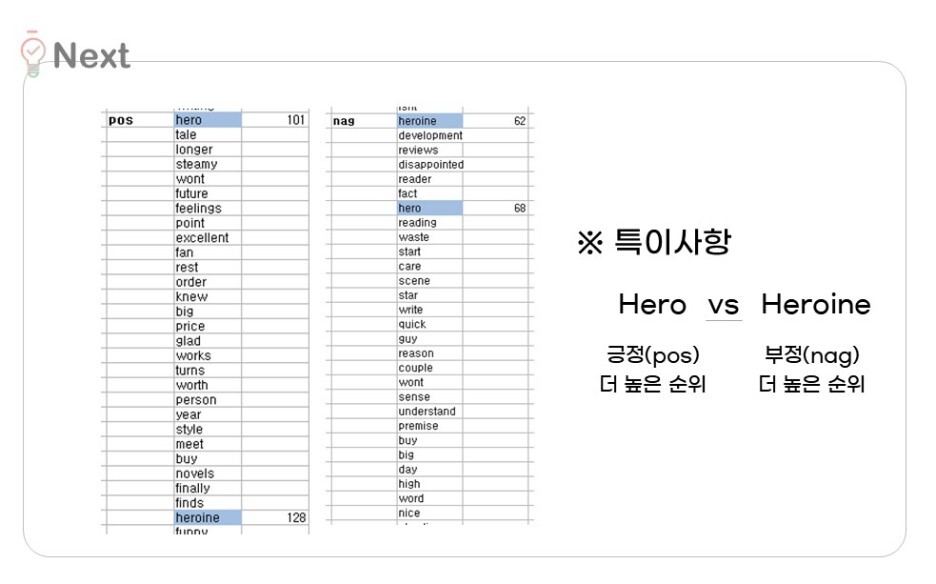
그러다 발견한 조금은.. 슬픈 소식..!?
4) 각각 남성과 여성의 영웅을 뜻하는 어휘가 있어서
신기해서 구체적으로 보니
Hero와 Heroine의 순위 양상이 서로 다르더라고요.
긍정에서는 Hero가 더 높게
부정에서는 Heroine이 더 높게 나왔어요.
아마 도서의 특성 상, 영웅보다는 주인공의 뜻에 가깝게 쓰인듯해요.
그때, 여성주인공이 부정리뷰에서 더 자주 언급되는거 같아요.

추가적으로ㅎㅎ
family(가족) 과 같이 신기한 소재도 발견!!
** 보완 3) 데이터 추가 Load **
[삼성 SDS Brightics] 개인 분석 프로젝트 : 주제 선정
안녕하세요.ㅎㅎ Brightics 서포터즈 3기 정민경입니다. 이제 활동의 막바지로 접어들어서 개인 분석 프로...
blog.naver.com
요거는 개인분석의 첫 시작, 그러니까 3주 전 포스팅인데요..!!
그때 하지 못했던 데이터를 로드하는데 성공했어요 - ☆★
(멘토님 덕분에ㅠㅠ)

그러니까 여러분 다들 Brightics 서포터즈 하세여
ㅎㅎ그냥 분석만 하고 끝나는 활동이 아니에요!!!

지난 오류 저번에 데이터를 가져오면서 아래의 두 문제를 만났죠
Q1. csv의 구분자 ,(콤마)가 내부 텍스트 데이터와 겹친다 !?
A♣ . 전체 구분자를 다른 기호(ex. tab)으로 변경한닷
Brightics에서 구분자를 바꿀 수 있는 기능을 봤지만,
어떻게 활용할 수 있나 궁금했는데
알고보니 파일 저장 시 구분자를 Tab으로 바꾸는 기능이 있더라고요!
+
게다가 'PC설정'에 들어가서
구분자를 사용자가 원하는 대로 바꾸는 기능을 알게되었는데
(그러면 콜론 및 세미콜론도 구분자로 가능)
텍스트에서는 Tab 이 가장 안 쓰일법 하잖아요!!
그렇기에 Tab 을 구분자로 진행했어요.


csv 다른 이름으로 저장 -> (탭으로 구분) / Brightics의 Load 중 구분자 tab으로 설정 Q2. 줄바꿈(enter)으로 인한 null
A♣. 찾아바꾸기로 줄바꿈 없애기 ( 단, csv 아닌 xlsx 에서 가능)
이거는 저도 이번에 너무너무 신기했던거ㅎㅎ
excel의 찾아바꾸기에 'ctrl + shift + j' 입력하면
아주 작은 점이 깜빡이기 시작해요.
바로 원하는 줄바꿈을 찾아주겠다는 거!!

그렇게 줄바꿈(enter)을 싹 공백(space)으로 바꾸었답니다
그 결과ㅎㅎ두구두구
데이터 가져오기에 성공했어요!!♥



book_genre google_books_1299 Review
원래.. 요번주 진도는 여기까지가 아니라 더 나가야하는데
해보고싶었던 데이터 Load 문제를 해결하면서
너무 기뻤던거 같아요. >_<
분석 내용이 더 풍부해질 수 있겠죠?
그리고 TF-IDF 순위를 보면서는
개인적인 궁금증도 해결할 수 있었어요.
그치만 도서리뷰만의 특성이 도드라지기 보다
흔히 영화리뷰에서도 볼 수 있는 어휘들이어서
대중평가의 보편적인 양상을 분석한듯 하고,
아마 비슷한 과정으로 추가한 데이터도 살펴보면서
분석을 확장시킬 듯 해요!ㅎㅎ
할 수 있겠죠?ㅋㅋ
그럼 담주에 살아서..?
돌아오겠습니다!ㅎㅎ

※본 포스팅은 삼성SDS Brightics 서포터즈 3기 활동의 일환으로 작성하였습니다
'삼성 Brightics 서포터즈' 카테고리의 다른 글
[삼성 SDS Brightics] 개인 분석 프로젝트 : word2vec (0) 2022.11.09 [삼성 SDS Brightics] 개인 분석 프로젝트 : 감정분석 및 분류 (0) 2022.11.02 [삼성 SDS Brightics] 개인 분석 프로젝트 : 데이터 EDA (1) 2022.10.19 [삼성 SDS Brightics] 개인 분석 프로젝트 : 데이터 전처리 (0) 2022.10.11 [삼성 SDS Brightics] 개인 분석 프로젝트 : 주제 선정 (0) 2022.10.04