-
[삼성 SDS Brightics] 개인 분석 프로젝트 : 데이터 전처리삼성 Brightics 서포터즈 2022. 10. 11. 23:47

안녕하세요.ㅎㅎ Brightics 서포터즈 3기 정민경입니다.
저번주에 이어 개인 분석 프로젝트를 진행하고 있는데요,
주제 선정을 거치고
이번주는 간략하게 전처리를 시도했어요.
아마 분석을 더 더 진행하면서
필요한 전처리가 또 생겨날 수 있겠다 싶어
요번이 완전한 전처리는 아니겠지만,
그래도 조금씩 시도하고 나아가고 있는
저의 Brightics 분석 소개를 시작합니다~

1) Delete Missing Data

가장 기본적으로 null 값
비어있는 데이터를 없애줍니다..!!
딱히 빈 칸이 보이지 않았는데요,
곳곳에 숨어있었는지
12,001 -> 11,997개로
4개의 데이터가 사라진 것을 확인할 수 있어요!

2) Tokenizer
그리고 자연어처리를 할 때 반드시 해야하는 작업,
Tokenizer(토큰화) 입니다.
문장을 최소 단위의 단어로 쪼개는 과정이자
품사를 태깅하여
각 단어가 문법적으로 어떤 역할을 하고있는지 알아내는데요,

그러면서 분석 시 내게 어떤 품사가 필요한지!
원래는 추려내는 코드를 작성해야해요,
하지만 Brightics에는 이를 손쉽게 고를 수 있도록
위와 같은 창이 있답니다.

그러면 단어로 조각난 list 형태로 문장이 저장된
tokenized_reviewText 를 볼 수 있어요.
제가 아직 자세히 살펴보지 않아 기본 설정으로 두었지만..
아시죠!?
어떤 품사에 문법적으로 주목하느냐도
단순히 의미를 파악하는 데에 그치지 않고
더 깊게 내재된 의미에 다가갈 힌트가 될 수 있다는 것
'명사/동사'에 주목할 때
'동사/형용사'에 주목할 때
'조사'에 주목할 때 등등…
예전에 각각의 경우마다 결과가 어떻게 달라질까
내가 놓친 부분은 없나 살펴봤던 게 기억나요.
그러한 여러 조합을 브라이틱스에서는
너무나 손쉽게 구현할 수 있어
제가 좋아하는 기능이에요ㅎㅎ

3) Stopwords Remover
그렇게 조각낸 단어들 중,
I, am, are, is, ...
포괄적인 의미로 자주 쓰이는 단어들
중요한 의미를 내포하지 않는 단어들
'불용어'라 하는데요,
분석의 정확도를 높이기 위해 요런 무의미한 단어를 제거할 거에요.
위에 tokenize 된 단어 목록에서 이어 진행하면 됩니다.
이때!! 불용어 목록은 한국어/영어 모두 구글에 검색하면
아래처럼 리스트를 제공해주는 여러 사이트가 있어요.


사이트마다 조금씩 불용어 목록이 다른데,
딱히 정답이 없는 문제라
오히려
분석 목적이자 맥락에 더 어울리는 것이 무엇일지 고르면 돼요.
그리고 csv 형태로 만들어
제거할 stopwords로 해당 데이터를
Load 해주고 연결하면 돼요!
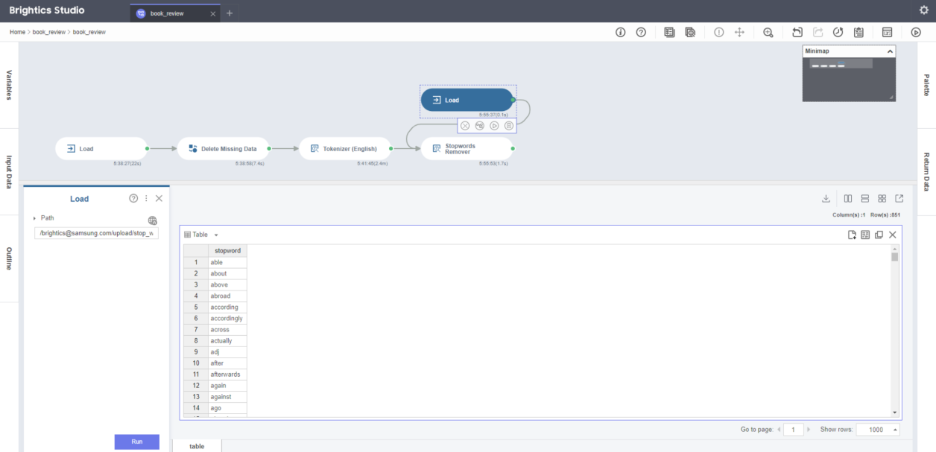
그렇게 실행하고 나면~

tokenized_reviewText 에 특정 단어들이
사라진 것을 볼 수 있어요.

텍스트 데이터의 성격 상
애매한 것을 최대한 제거하는 과정이 필요한데,
분석이 더 용이하고 깔끔해지도록,
한 단계를 거친 것입니다.ㅎㅎ
Reivew
여기까지 총 3단계가
텍스트 데이터에 필요한 전처리라 볼 수 있어요.
그 외 rating(점수)의 긍정/부정을 나누고
리뷰를 단 날짜도 적혀있어 해당 시간을 분류해볼까도 고민중인데요,
또 summary(요약)와의 관계까지.
아마 어떤 기준이 적절할지
다음주에 본격적으로 데이터를 탐색하며
차차 찾아가려합니다.
말그대로 도서에서는 어떤 느낌이자 단어가
리뷰에 등장하는지 궁금해서요 :)

그럼 담주에 이어 만나요!ㅎㅎ
※본 포스팅은 삼성SDS Brightics 서포터즈 3기 활동의 일환으로 작성하였습니다
'삼성 Brightics 서포터즈' 카테고리의 다른 글
[삼성 SDS Brightics] 개인 분석 프로젝트 : TF-IDF (0) 2022.10.26 [삼성 SDS Brightics] 개인 분석 프로젝트 : 데이터 EDA (1) 2022.10.19 [삼성 SDS Brightics] 개인 분석 프로젝트 : 주제 선정 (0) 2022.10.04 [삼성 SDS Brightics] 팀 영상 편집_끝 :) (0) 2022.09.27 [삼성 SDS Brightics] 팀 영상 촬영_발연기ㅎㅎㅎ (1) 2022.09.21