-
[삼성 SDS Brightics] 개인 분석 프로젝트 : 데이터 EDA삼성 Brightics 서포터즈 2022. 10. 19. 00:01

안녕하세요.ㅎㅎ Brightics 서포터즈 3기 정민경입니다.
지지난주부터 계속 하고있는 저의 개인 분석 프로젝트!!
이어 포스팅합니다.ㅎㅎ
저번주까지 전처리를 시도했다면
조금씩 분석하는 곳까지 나아갔어요!
그럼 시작합니다아

1) 긍정/부정 리뷰 분류

먼저 rating(점수) 기준으로
각 리뷰를 긍정/부정으로 나누는 작업을 진행했어요
'Add Cloumn' 기능을 통해
조건을 주어 emotion을 추가!
1~5점 분류로 3점이 '보통'이자 딱 정중앙이 되는
애매한 지점이 있는데요,
분석을 진행하면서 3점을 pos/nag 또는 so-so
어떻게 분류할때 적합할지 더 살펴볼 거 같아요.

일단은 갯수를 고려해서
4-5점 pos(긍정), 1-3점 nag(부정)으로 카테고리화!
** 연도 분류 **
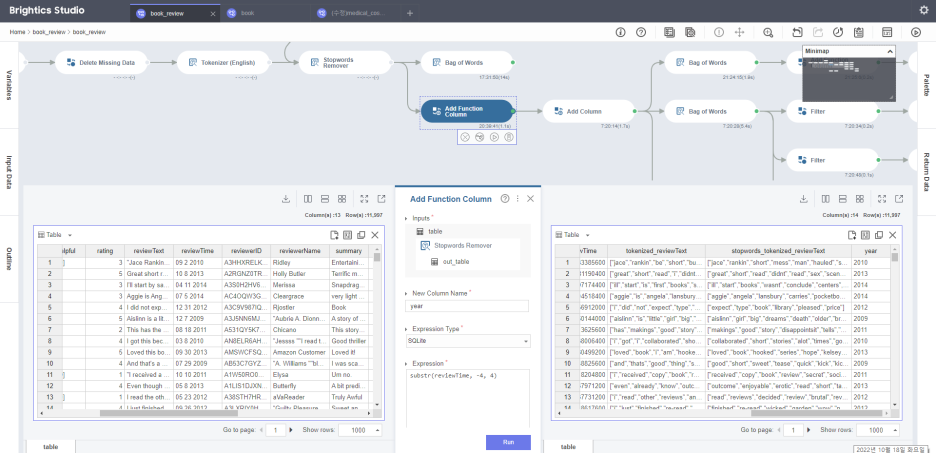
위에 emotion을 추가하면서 같이 작업했는데요,
reviewTime(리뷰날짜)가 적혀있어서
그렇다면 연도를 나중에 고려해보면 어떨까?라는 궁금증에
'Add Function Cloumn' 을 통해
이번에는 수식이자 내장함수로 year(연도)를 추가!!
"일 월 년도"
String(문자열) 형태로 적혀있는 것에서
SQLite : substr( 문자, 시작부분, 갯수)
= substr( reivewTime, -4, 4)
이렇게 끝에서부터 4자리 문자열을 가지고왔답니다.

문자열을 어떻게 가지고 와야하나~
구현하면서 또 나름 공부가 되었던 내용인데요,
Brightics를 쓸때마다 느끼지만
이렇게 다른 분석언어(python, sqlite)와 연동 되는 것이
기능을 제한없이, 얼마든지 확장할 수 있다는 거라
항상 매력적이라 느껴요.ㅎㅎ
물론..!! 알 수 없는 오류 뜰때는 어렵지만ㅋㅋㅋ
2) Bag of Words
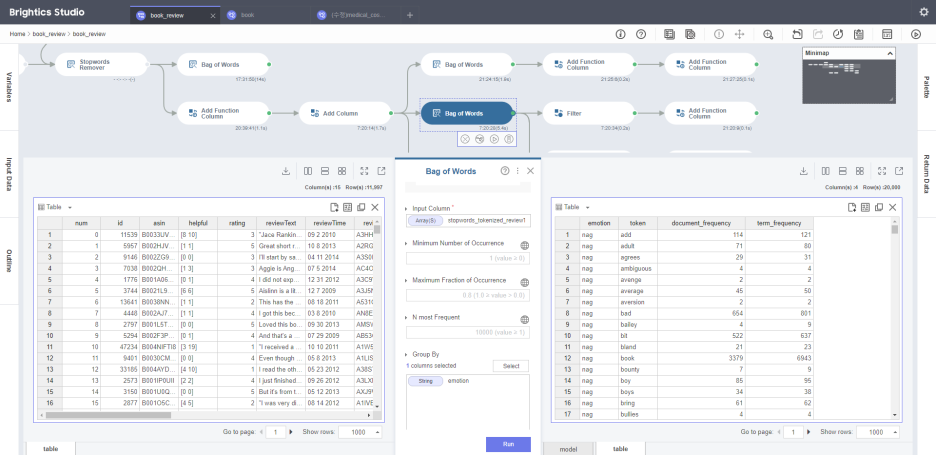
그 다음,
document_frequency(문서출현빈도)
term_frequency(단어출현빈도)
두 사항을 세어주는 'Bag of Words' 시도!
Group by로 emotion 변수를 주면서
긍정/부정 각각 어떤 단어가 자주 출현하나 나눠봤어요.
그런데 그럼 기준이 2개가 되는거잖아요.
단어가 등장한 리뷰에 몇개인가 / 단어자체가 몇번 등장하는가
두 기준 중 어느것이 적절할까.. 고민하다
둘을 함께 살펴보는 TF-IDF로 고고했답니다.ㅎㅎ

3) TF-IDF

Brightics 안에 'TF-IDF' 기능이 있어서
해당 함수로 살펴보기도했고요,

TF-IDF 란 무엇일까, 내용을 찾아보며
식을 직접 구현해서 추가해보기도 했어요.
그런데...
둘이 결과가 같았는가...!!

ㅎㅎ달랐답니다. 그래서
왜 그런건지 더 알아봐야할 거 같아요.
완전 다른건 아니고!
상위권에 있는 어휘의 전반적 양상은 비슷했는데요,
세부적인 순위가 조금씩 달랐어요.
그런게 또 나중에 중요해질 수 있으니!!
정확하게 해보고 가면 좋겠죠?


그래도 둘 다 추후 작업은 똑같아요!
'Filter'로
emotion == pos / nag 나누어 결과를 보면
다운로드 icon click


짜라란. csv로 저장해서
TF-IDF 순위로 내림차순 한 다음에
긍정/부정에 나타나는 어휘들이 어떻게 다른지 구체적으로 살펴보려해요.

Review
사실 요번주에 조금 미리ㅎㅎ 살펴봤답니다.

안보이게 스포 흥미로운 것도 있었고
아, 여기를 더 보완해야겠다라는 것도 있었고
여러 생각이 들었는데요,
TF-IDF란 무엇인지 원리를 바탕으로
도서리뷰의 어휘들을 분석해보려해요.

담주에!ㅎㅎ
※본 포스팅은 삼성SDS Brightics 서포터즈 3기 활동의 일환으로 작성하였습니다
'삼성 Brightics 서포터즈' 카테고리의 다른 글
[삼성 SDS Brightics] 개인 분석 프로젝트 : 감정분석 및 분류 (0) 2022.11.02 [삼성 SDS Brightics] 개인 분석 프로젝트 : TF-IDF (0) 2022.10.26 [삼성 SDS Brightics] 개인 분석 프로젝트 : 데이터 전처리 (0) 2022.10.11 [삼성 SDS Brightics] 개인 분석 프로젝트 : 주제 선정 (0) 2022.10.04 [삼성 SDS Brightics] 팀 영상 편집_끝 :) (0) 2022.09.27