-
[삼성 SDS Brightics] 팀 분석의 끝자락♥카테고리 없음 2022. 9. 6. 22:46

안녕하세요.ㅎㅎ Brightics 서포터즈 3기 정민경입니다.
저번주로 개인의료비예측 : 팀분석 프로젝트를 마치고
이번주에는 팀원들과 분석내용을 정리하고
관련 영상기획을 위해 모였어요!
Brightics를 쓰면서 분석이 휙휙 진행되던 와중에
그동안 해온 내용을 본격적으로 정리해보자
PPT가 50장을 넘겼답니다..ㅎㅎ
데이터 하나의 분석이 역시 간단하지않구나
다시 한 번 느끼면서
다같이 만나서 한 장 한 장 살펴보며
구체적인 흐름과 내용을 정리했어요 :)
1) 개요

짠, 보고서의 첫 시작-★


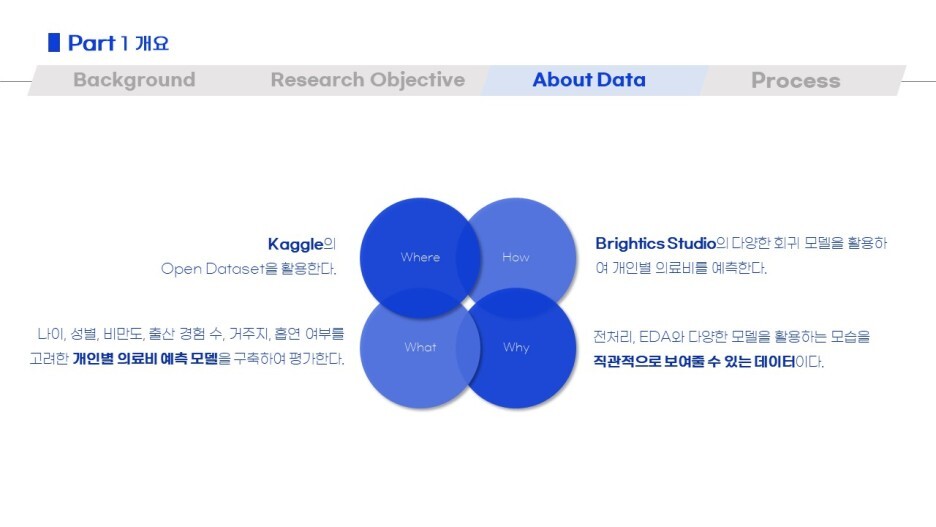

가장 먼저 위와 같이 주제와 목적, 데이터셋을 정리했어요!
한국의 의료비 관련 최신 현황과 보험 상품기획에 쓰일 수 있음을 언급하며
우리가 어디서 데이터를 가져왔는지
각 column들은 어떤 의미를 지니는지 정리했답니다.
2) 데이터 탐색(EDA)
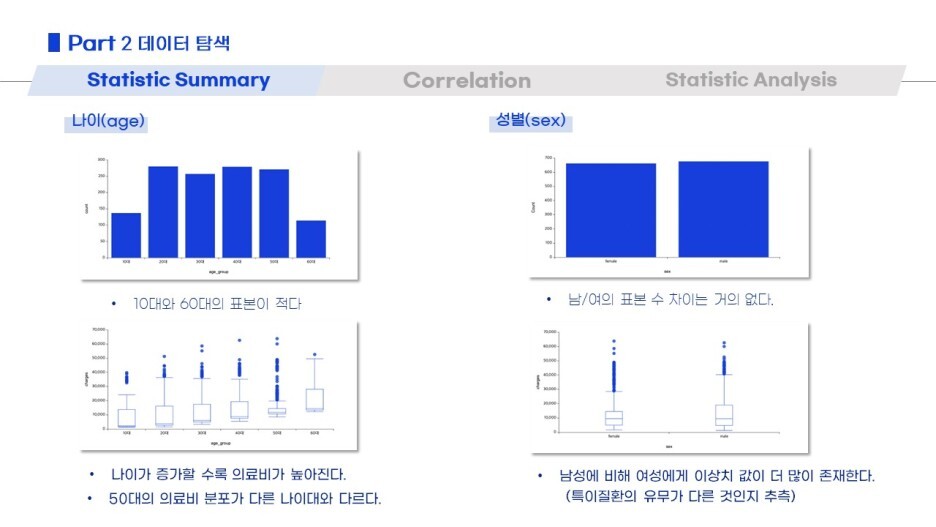
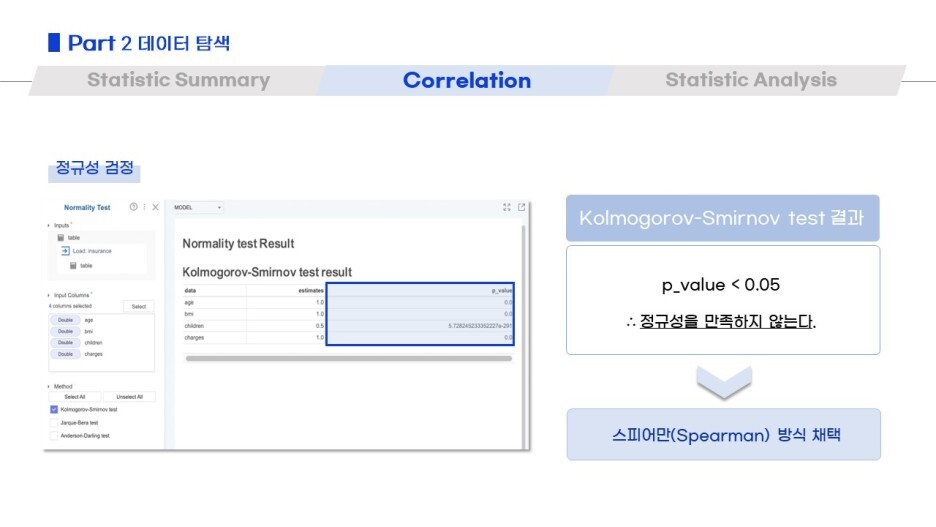
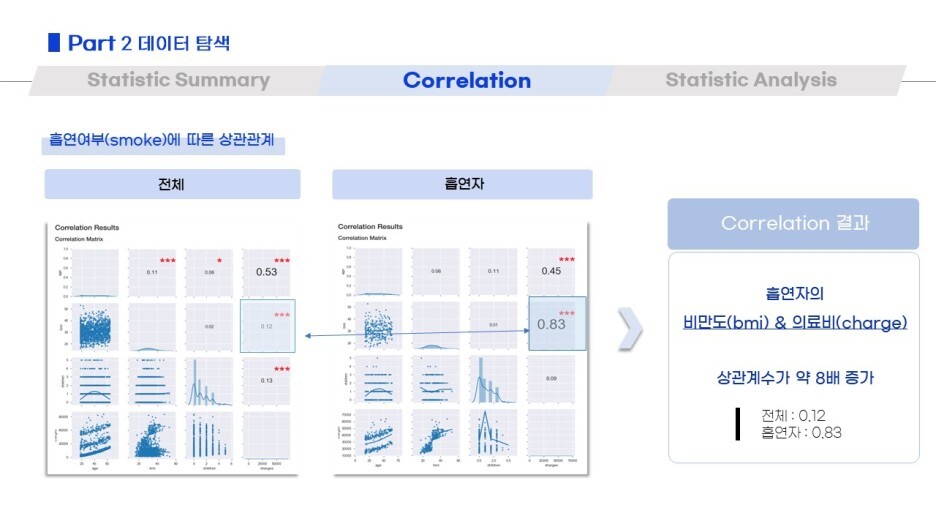
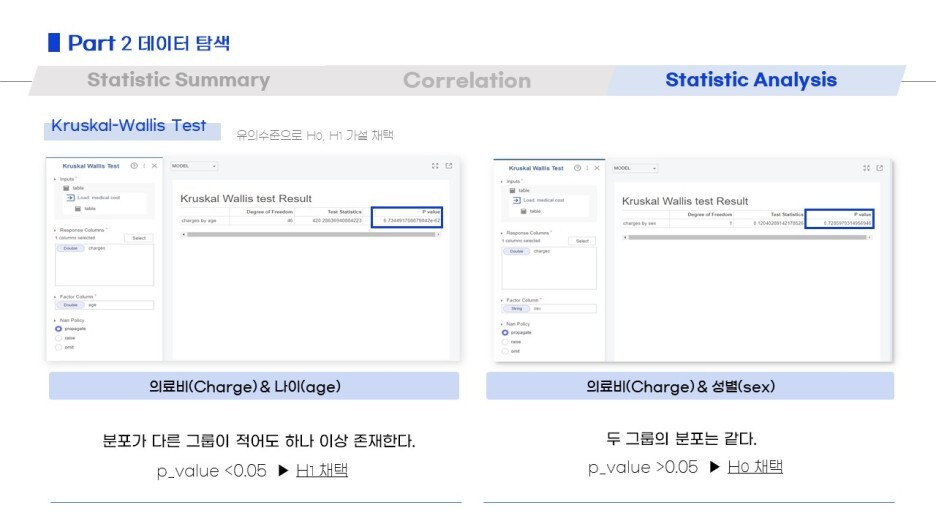
그리고 box plot / correlation / chi squre test of indepence 와 같이
데이터탐색을 여러 방법으로 진행했어요!
3) 데이터 전처리

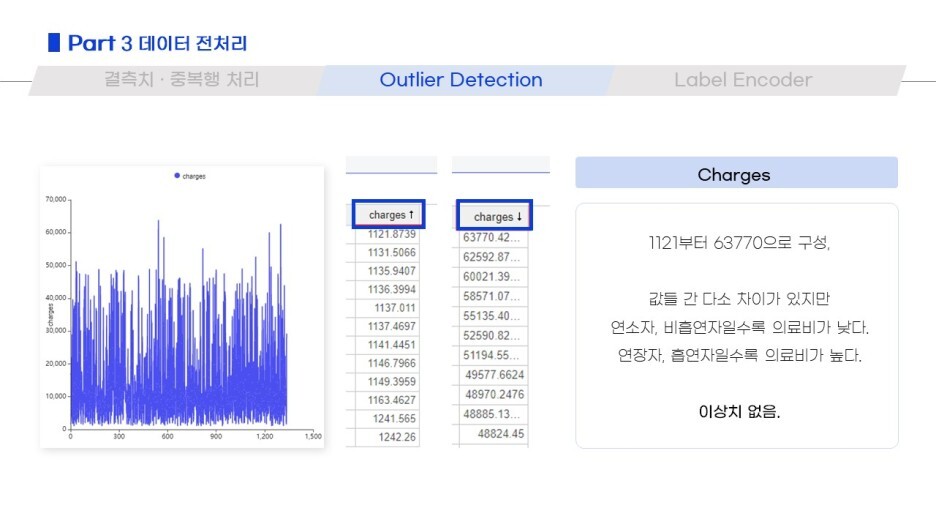
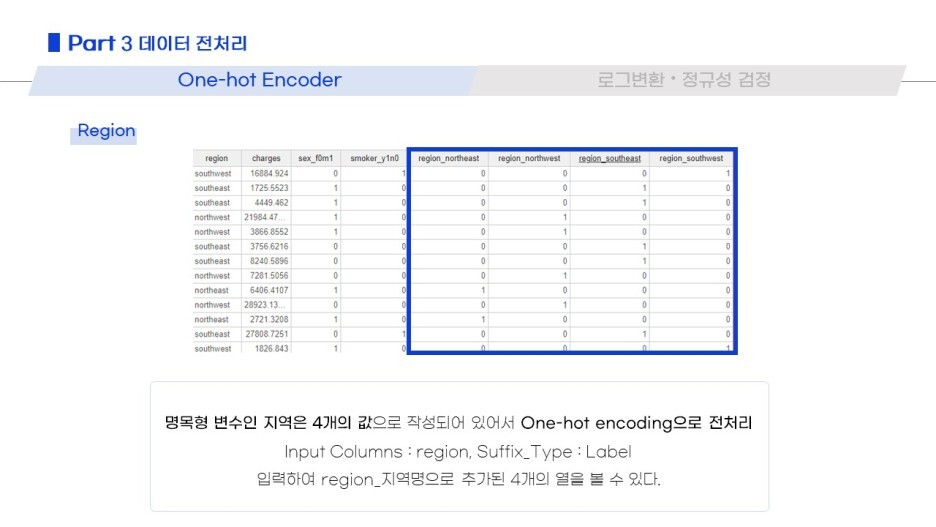
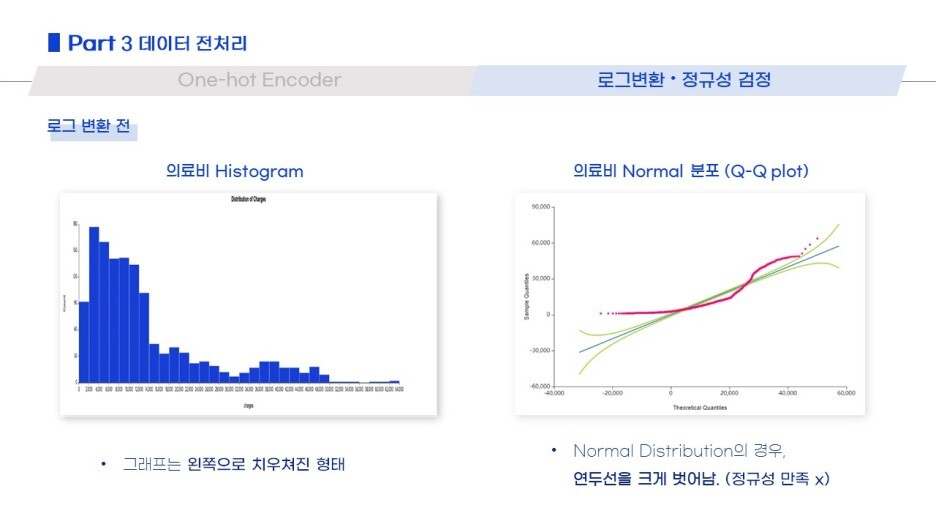
그 후, 결측행 및 중복행 처리 / 이상치 제거 / encoder / 로그변환
모델링을 진행하기 전 필요한 전처리를 거쳤습니다!
4) 데이터 모델링
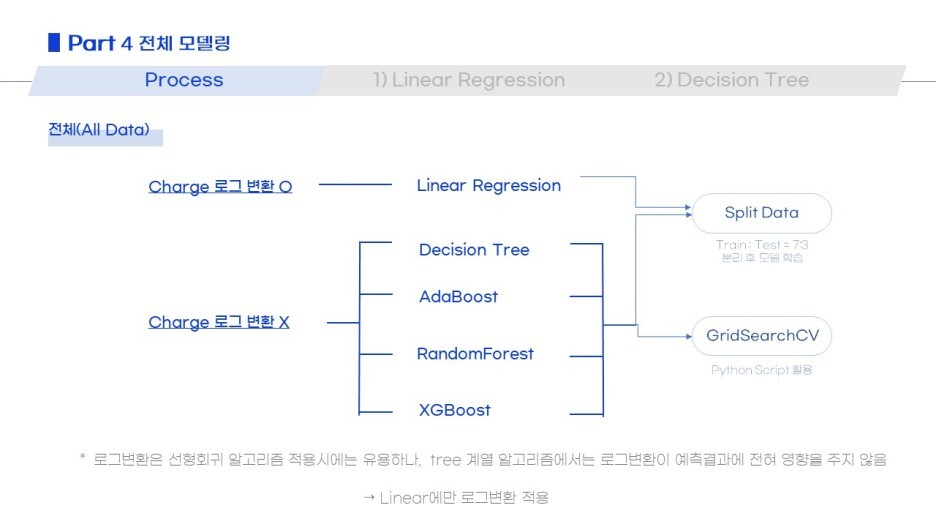
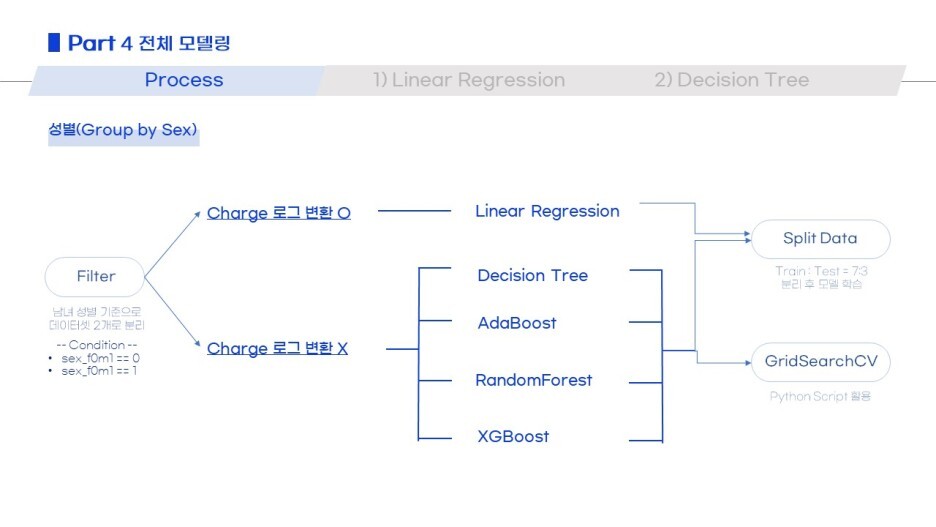
데이터 모델링은 전체로 한 번, 성별로 나누어서 한 번.
그리고 각각에 5가지 모델을 적용했어요.
Linear / Decision Tree / Adaboost / RandomForest / XGBoost
그런데 모델마다 데이터전처리 과정이 달라서!
(로그변환이 오히려 모델을 무겁게 할 수 있다는 피드백을 듣고)
Linear에만 의료비의 로그변환을 적용한 내용입니다.
이때, Brightics에 내장된 함수로 각 모델 별 Regression train 과 predict 후(split 적용)
뿐만 아니라 python을 더해서 쓸 수 있는 기능을 활용해
코드로 GridsearchCV를 적용해 비교해 보았네요!
특히 여기가 조금 복잡했던 거 같아요. 시도해본 내용이 많다보니
우리가 무엇을 어떻게 해왔는지 이해한 바를 맞춰나갔네요ㅎㅎ
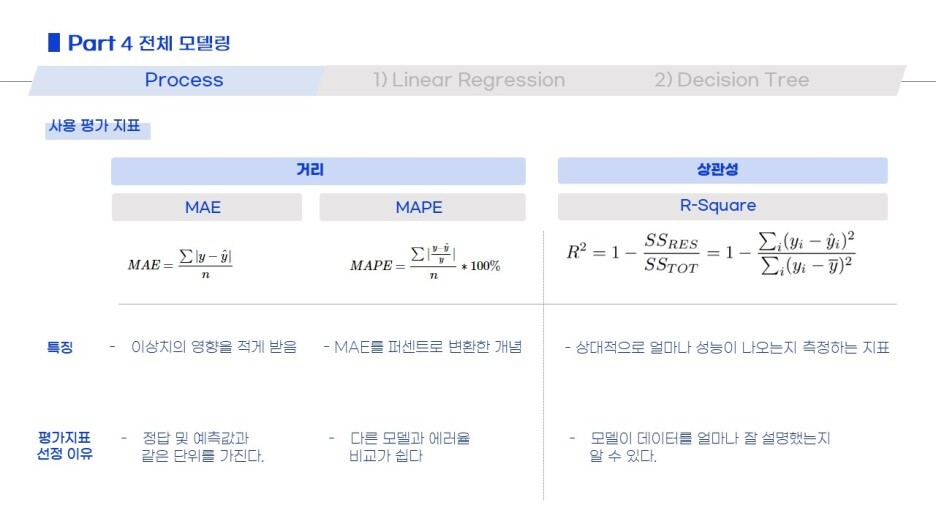
우리가 사용한 평가지표도 요렇게 정리하고!

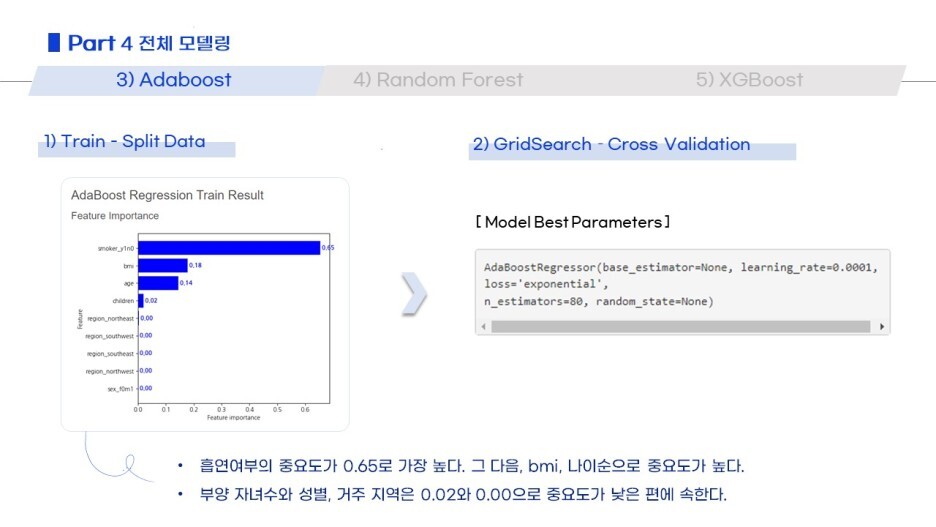
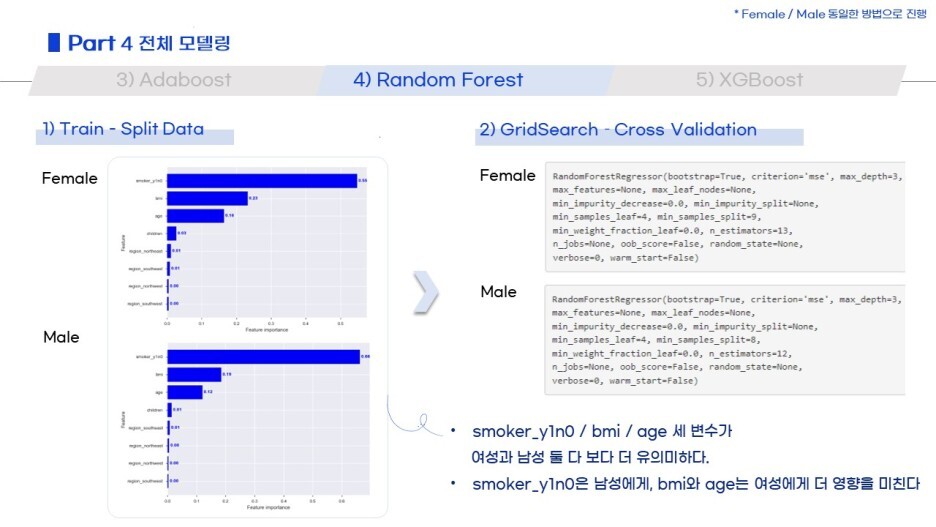
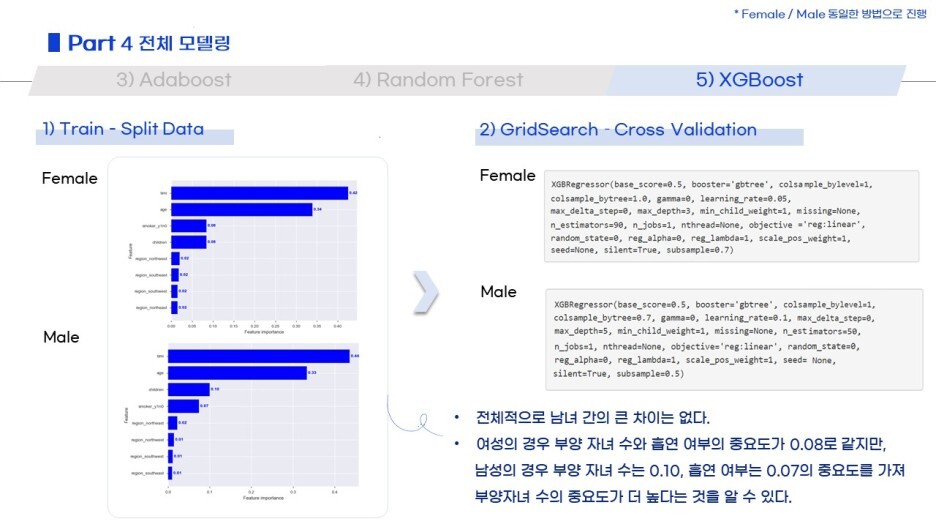
각 모델별로 어떤 변수가 중요했는지, GridSearchCV 결과가 어떠했는지
짧막하게 정리했습니다.

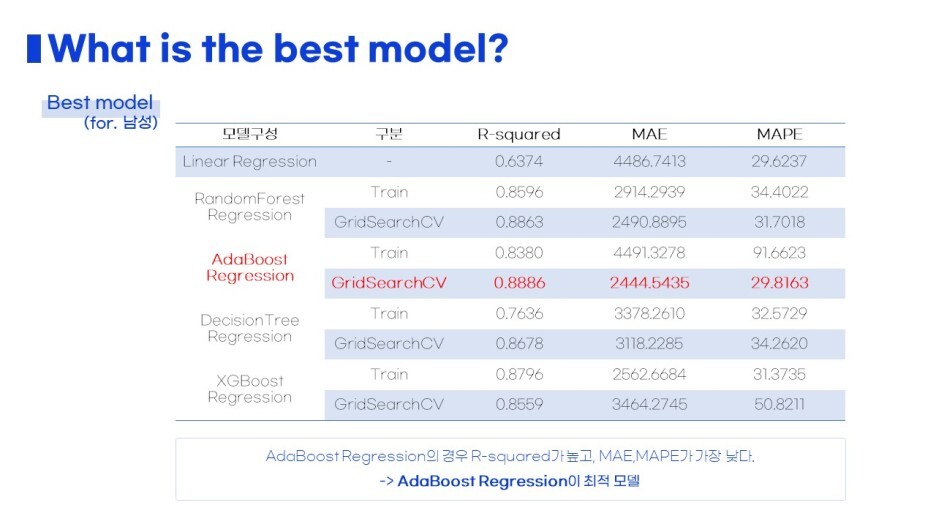
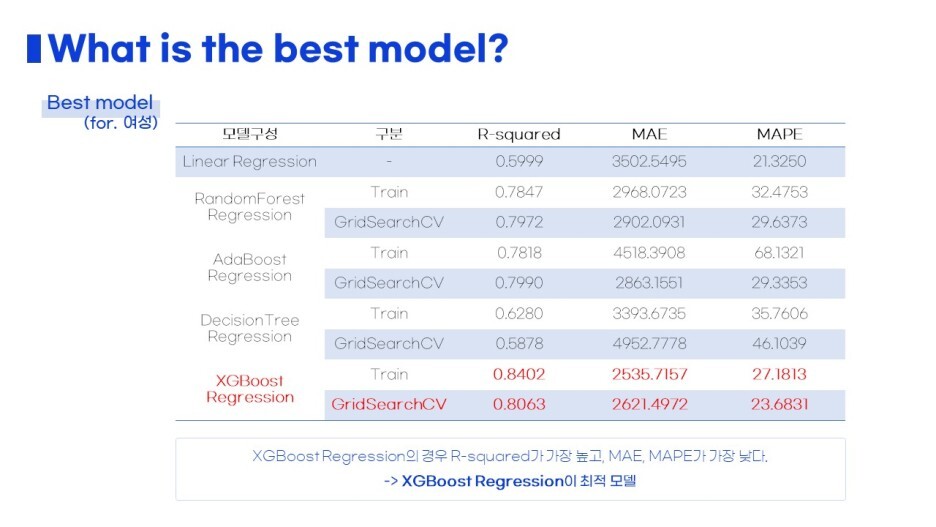
그렇게 각각 어떤 모델의 성능이 가장 좋았는지
평가지표를 한 눈에 보기좋게 나타냈습니다 :)
5) 결론
분석과 모델링 결과, 최종적으로
의료비 관련하여 어떤 요소를 중점적으로 다뤄야하는지
간략하게 살펴보며 마무리 지었어요.
성별 뿐만 아니라 다른 요소(흡연, 지역...)로 나누어서
모델링을 시도해보지 못한 점
나아가 kaggle의 미국 데이터를 활용했는데
한국으로 확장시켜 보지 못한 것...!!
(타이밍 상 그러지 못했네요ㅠ)
팀원들과 함께하니까 색다른 insight를 얻을 수 있었던 기억에
그런 점이 나름의 아쉬움으로 남았네요.
Reivew
팀프로젝트이기도 하고
데이터분석은 특히 '어떻게 해야 사람들에게 효과적으로 전할 수 있을까'가
보고서를 만들 때 최대 고민거리가 되어요.
이번에도 팀원들이랑 그런 고민을 하면서
서로 내용을 교정하고 정정했어요 :)
아, 거기에 이 프로젝트를 활용해
영상을 제작할 예정인데요.
이를 위해 주말에 오프라인 만남을 가지고
대본 작업을 거치고있네요ㅎㅎ
자랑 하나 하자면.. 리더가 깜짝 투썸 cake를 사주더라구요.
디저트에 환장하는 저는
달콤하게(?) 회의를..(?)
ㅋㅋ컨셉과 주제가 무엇인지!
추후 포스팅도 기대해주세요. :▷
※본 포스팅은 삼성SDS Brightics 서포터즈 3기 활동의 일환으로 작성하였습니다